「イメージPDFファイルの処理」の編集履歴(バックアップ)一覧に戻る
let ExtractOperation (msgcb:msgCallback) (endcb:endCallback) (sourcePdf:string) outputPath = createDirectory outputPath let pdf = new PdfReader(sourcePdf) List.iter (OnePageFrom msgcb outputPath pdf) [1..pdf.NumberOfPages]
let OnePageFrom (msgcb:msgCallback) outputPath (pdf:PdfReader) (page:int) = let pg = pdf.GetPageN(page) getImages outputPath pg pdf page
let getImages outputPath (dict:PdfDictionary) (doc:PdfReader) page = let res = PdfReader.GetPdfObject(dict.Get(PdfName.RESOURCES)) :?> PdfDictionary let xobj = PdfReader.GetPdfObject(res.Get(PdfName.XOBJECT)) :?> PdfDictionary getPdfObjects xobj doc |> Seq.iter (saveImage outputPath page)
let getImage (doc:PdfReader) (theObj:PdfObject) =
let tg = PdfReader.GetPdfObject(theObj) :?> PdfDictionary
let subtype = PdfReader.GetPdfObject(tg.Get(PdfName.SUBTYPE)) :?> PdfName
if PdfName.IMAGE.Equals(subtype) then
let xrefIdx = (theObj :?> PRIndirectReference).Number
let pdfObj = doc.GetPdfObject(xrefIdx)
let str = pdfObj :?> PdfStream
let filter = tg.Get(PdfName.FILTER).ToString()
match filter with
| "/FlateDecode" -> None
| _ -> Some(PdfReader.GetStreamBytesRaw(str :?> PRStream))
else
None
let getPdfObjects (xobj:PdfDictionary) (doc:PdfReader) =
seq {
match xobj with
| null -> ()
| xobj ->
for key in xobj.Keys do
let theObj = xobj.Get(key)
if theObj.IsIndirect() then
yield getImage doc theObj
}
let parms = new System.Drawing.Imaging.EncoderParameters(1)
parms.Param.[0] <- new System.Drawing.Imaging.EncoderParameter(System.Drawing.Imaging.Encoder.Compression, byte 12)
let saveImage outputPath pageNumber (img:byte[] option) =
match img with
| None -> ()
| Some image ->
use memStream = new System.IO.MemoryStream(image)
memStream.Position <- 0L
use img = System.Drawing.Image.FromStream(memStream)
let path = System.IO.Path.Combine(outputPath, System.String.Format(tempFileFormat, pageNumber, 1))
match jpegEncoder with
| None -> ()
| Some enc -> img.Save(path, enc, parms)
let CreatePdf outputPath aspectRatio numOfPage =
let margin = 0.0f
let document = new Document(new iTextSharp.text.Rectangle(0.0f, 0.0f, PageSize.A4.Width, PageSize.A4.Width * aspectRatio),
margin, margin, margin, margin)
PdfWriter.GetInstance(document, new System.IO.FileStream(outputPath, System.IO.FileMode.Create)) |> ignore
document.Open ()
List.iter (addOnePage document aspectRatio) [1..numOfPage]
document.Close();
let addOnePage (document:Document) aspectRatio pageNum = let path = System.IO.Path.Combine(effectedTempPath, System.String.Format(tempFileFormat, pageNum, 1)) let jpeg = iTextSharp.text.Image.GetInstance(path) jpeg.SetAbsolutePosition(0.0f, 0.0f) jpeg.ScaleToFit(PageSize.A4.Width, PageSize.A4.Width * aspectRatio) document.Add jpeg |> ignore document.NewPage() |> ignore
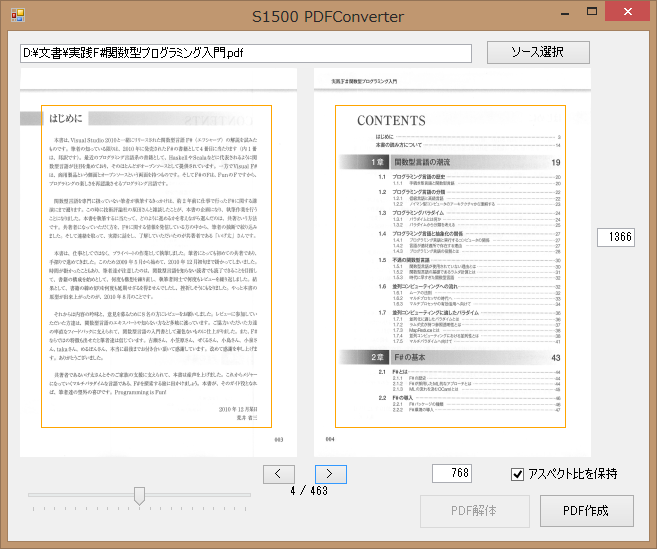
PDFConvertLib.ExtractImagesFromPDF(
delegate(string msg){
var deleg = new MessageDelegate(ExtractImageMsg);
var ret = this.BeginInvoke(deleg, new object[] {msg});
},
delegate() {
var deleg = new EndDelegate(ExtractImageEndOperation);
var ret = this.BeginInvoke(deleg, new object[]{});
},
filePath.Text, PDFConvertLib.outputTempPath
);
let OnePageFrom (msgcb:msgCallback) outputPath (pdf:PdfReader) (page:int) =
let pg = pdf.GetPageN(page)
getImages outputPath pg pdf page
sprintf "%A %d" pdf page |>
msgcb.Invoke // ← ココで呼びだし!
let ExtractOperation (msgcb:msgCallback) (endcb:endCallback) (sourcePdf:string) outputPath =
async {
createDirectory outputPath
let pdf = new PdfReader(sourcePdf)
List.map (ThreadRoundRobbin (OnePageFrom msgcb outputPath pdf) pdf.NumberOfPages numberOfThreads) [1..numberOfThreads] |>
Async.Parallel |>
Async.RunSynchronously |> ignore
endcb.Invoke () // ← ココで呼びだし!
}
let ExtractImagesFromPDF (msgcb:msgCallback) (endcb:endCallback) (sourcePdf:string) outputPath =
ExtractOperation msgcb endcb sourcePdf outputPath |>
Async.Start |> ignore
let ExtractOperation (msgcb:msgCallback) (endcb:endCallback) (sourcePdf:string) outputPath =
async {
createDirectory outputPath
let pdf = new PdfReader(sourcePdf)
List.iter (OnePageFrom msgcb outputPath pdf) [1..pdf.NumberOfPages]
endcb.Invoke ()
}
let ThreadRoundRobbin theMethod max cntThread n =
async {
List.iter theMethod [n..cntThread..max]
}
let ExtractOperation (msgcb:msgCallback) (endcb:endCallback) (sourcePdf:string) outputPath =
async {
createDirectory outputPath
let pdf = new PdfReader(sourcePdf)
List.map (ThreadRoundRobbin (OnePageFrom msgcb outputPath pdf) pdf.NumberOfPages numberOfThreads) [1..numberOfThreads] |>
Async.Parallel |>
Async.RunSynchronously |> ignore
endcb.Invoke ()
}
