降水量データをステーションごとに分ける作業
今回扱う降水量データの量が多く、処理するのが大変なので、ステーションごとのファイルに分けましょ
今回のところはステーション番号と各ステーションを持つデータ数をチェックするだけです
元データを取り込む
今回扱うデータは、1961~2007年各ステーションの日降水量データ「buchashuju.txt」です。
データがある場所は、O:\学生個人用フォルダ\you\研究データです。
(データのサイズが大きいため、コピーせず、o:ドライブをつながったまま作業してください)
rubyを用いた作業
では、エディターを立ち上げ以下のように入力します。ファイル名は「buchashuju.rb」とし、新しいフォルダを作り、その中で保存してください(前回と同じフォルダでも構わない。私の場合はC:\GIS\china\buchashujuに入れました)。
「buchashuju.rb」スクリプトの内容
file = "o:/学生個人用フォルダ/you/研究データ/buchashuju.txt"
n_line = 0; rec_number = 0 #rec_numberはレコード番号
number_before = 0 #number_beforeは前のステーション番号
open(file).each do |line| #fileを開き、各行に対して以下の作 業をおこなう
v = line.chop.split #vはarray と同じ、配列の意味
station_number = v[0] # v[0]は配列の最初の列
if station_number != number_before #"!="は"≠"
if rec_number > 0 # ">"は普段通り、0より大きいの意味
p [station_number,rec_number]
#1個以上の配列を表示するするのが"[]"を使う、pはputs
rec_number = 0 #rec_numberをまた0に戻る
end
end
number_before = station_number
n_line += 1 ; rec_number += 1
# 1を足す方法は2つある: ①n_line = n_line + 1 ②n_line += 1
end
puts n_line
buchashuju.rbの説明:
- n_line = 0; rec_number = 0; number_before = 0と定義する
- ファイルを開き、以下のことを一行一行でやる
- 行末の“Enter”を消し、“,”で分けたデータを配列Vに代入する
- 配列Vの最初の列をstation_numberに入れる
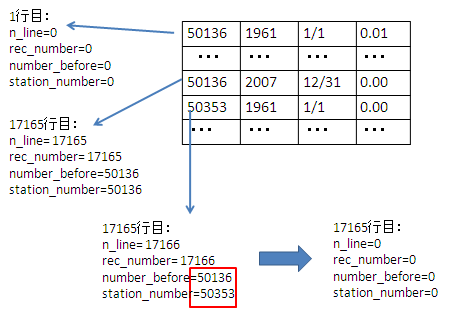
- もし、 station_number とnumber_beforeが等しくない
- そしてrec_number > 0の場合
- station_numberとrec_numberを表示する
- その後、rec_number が0に戻る
- number_before はstation_number を代入
- n_lineと rec_numberは行数とともに増加する
例:
では、コマンドプロンプトを立ち上げて下さい。
cd というコマンドで「buchashuju.rb」が存在するディレクトリまで移動します。
ここで、
ruby buchashuju.rb
と打つと表示されます。
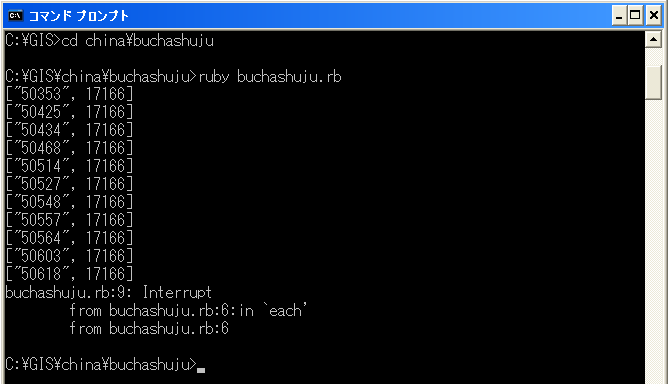
途中で止めたいならCtrlを押しながらcを押してください。
今回はここまでになります。
お疲れ様でした。
最終更新:2010年07月06日 21:19

