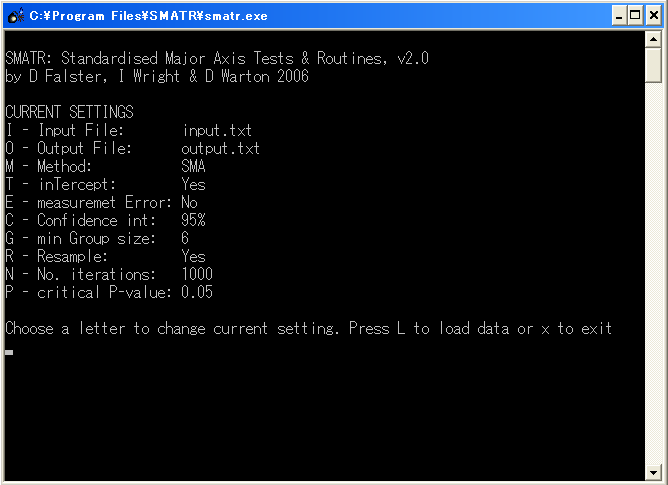
I - Input File: 読み込むデータファイルの名前を指定するコマンド。デフォルトはinput.txt。先ほどファイルネームをinputとしたのはこのため。必要があれば変更する。
O - Output File: 結果を出力するファイルネームを指定するコマンド。デフォルトはoutput.txt。(S)MATRのあるフォルダに勝手に生成される。
M - Method: 統計方法。デフォルトはSMA。ほかには通常の回帰(Ordinary Least Squares Regression)、主軸(Major axis)が用意されている。あえてこれらの回帰の方法の比較をしたいのでなければ変更する必要はありません。
T - inTercept: RMA回帰を行うときに、原点を強制的に通すかどうかの設定する。通常は必要なし。
E - measurement Error: 測定に伴う誤差を(RMAでも何でも)回帰に反映させるためのコマンド。これを計算するためには、同じデータを繰り返し取ってみて、その繰り返し取られたデータを用いて測定そのものにどのぐらいの誤差が含まれるか検討する。通常同じデータを何度も取れる状況にはないので、重要なことだが使うことは少ないかも。
C - Confidence int: 信頼区間。デフォルトは95%。
G - min Group size: RMA回帰時に、最低必要なデータ数。デフォルトは6。
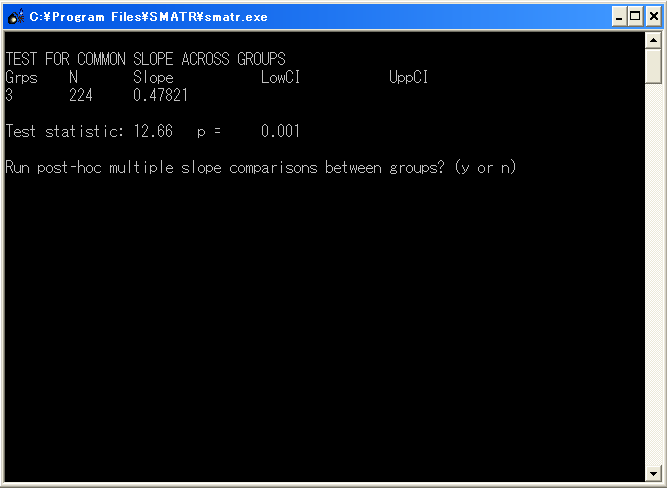
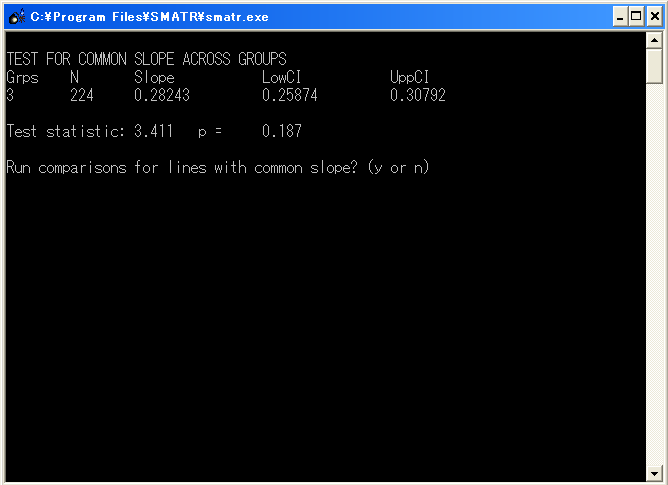
R - Resample: 傾きの検定をするときに、デフォルトのならべかえ検定するか、Χ2分布を用いた尤度比検定を行うか選択。通常はならべかえ検定。
N - No. Iterations: 傾きの検定時に行われる並べ替えの繰り返し数。デフォルトは1000。p < 0.01以下の確率で並べ替えを行いたいときは5000とする。
P - Critical p-value: 有意とする確率。デフォルトは0.05。
変更する場合は、変更したいコマンドを入力しEnterする。いじるとしたらi、o、nぐらいかな?
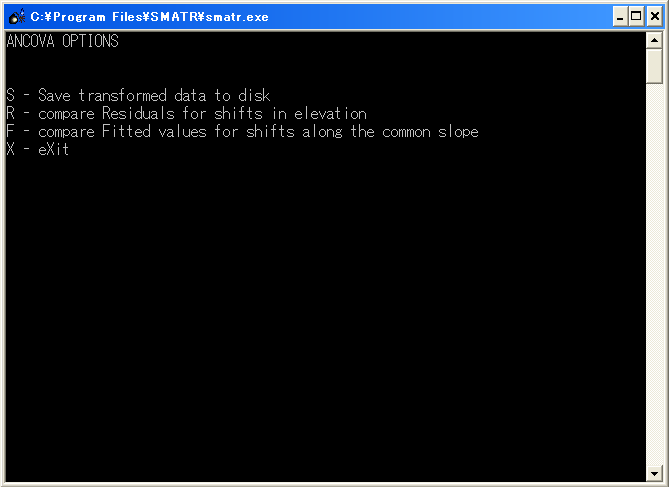
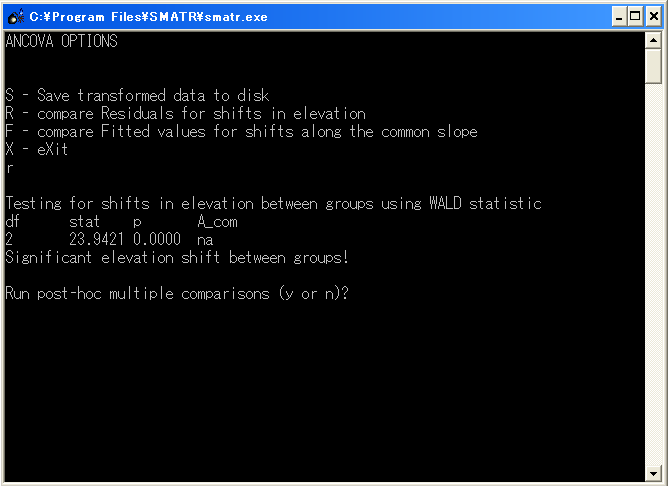
設定が終了したら、lを入力しEnterする。すると図2のような画面に移る。
図2
この画面では、読み込んだデータの認識方法に関する設定を行う。
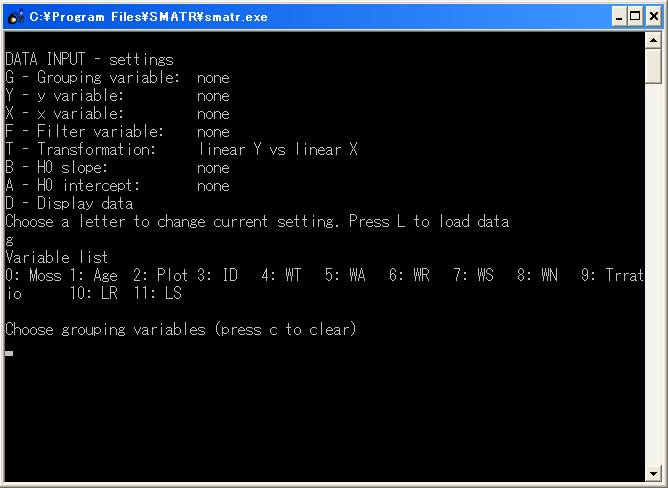
G - Grouping variable: グループ変数。いわゆる目的する処理を示している列。Gと入力してEnterすると、先ほどExcelで入力したデータファイルの1行目にあるラベルが並び、どのラベルがグループ変数なのかを聞いてくる。ラベルは数字で参照されているので、目的のラベルを示している数字を入力し、Enterする。
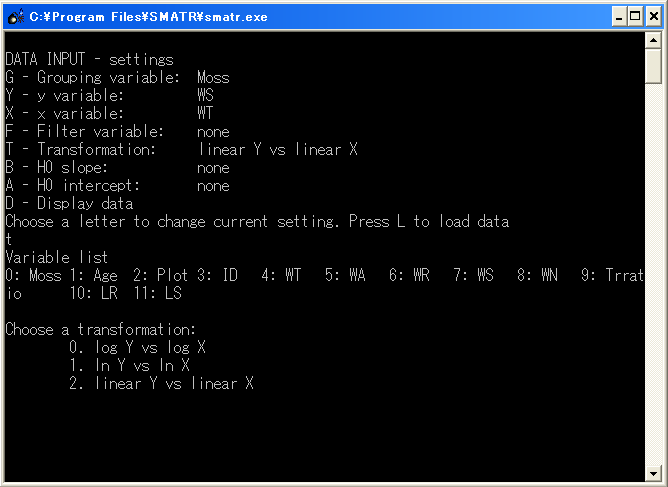
Y - y variables: Y軸にくる変数。選択法はGと同じ。
X - x variables: X軸にくる変数。選択法はGと同じ
F - Filter variable: フィルター変数。
T - Transformation: データ変換。デフォルトはX-Yが直線-直線 (つまり無変換)。XとYに関し、無変換のままか、対数変換するかが選択できる。わざわざ対数変換したデータを読み込ませる必要がない。これはこのソフトの優秀なところ。
A - H0 slope: あるひとつのRMA回帰に関し、得られる傾きがここで設定する値と有意に異なるかどうかを検定できる。2つ以上のRMA回帰間で関数関係を検討する場合はまったく無意味な設定。
B - H0 intercept: あるひとつのRMA回帰に関し、得られる切片がここで設定する値と有意に異なるかどうかを検定できる。2つ以上のRMA回帰間で関数関係を検討する場合はまったく無意味な設定。
Sokal, R.R., and Rohlf, E.J. 1995. Biometry: the principles and practice of statistics in biological research, 3rd edition. W.H.Freeman, San Francisco.
Shibuya, M., Hasaba, H., Yajima, T., and Takahashi, K. 2005. Effect of thinning on allometry and needle-age distribution of trees in natural Abies stands of northern Japan. J. For. Res. 10 (1); 15-20.
Cho, M., Kawamura, K., and Takeda, H. 2005. Sapling architecture and growth in the co-occurring species Castanopsis cuspidata and Quercus glauca in a secondary forest in western Japan. J. For. Res. 10 (2): 143-150.