<ごきげんよう>を見ていて、そこで使われているサイコロの特定の目がでやすいような気がしてなりません。特に!その目は『今日の当たり目』といって、出ると視聴者にプレゼントが当たるというものです。
そこで、1ヶ月番組を見ながらどの目が幾つ出たかチェックしてみました。1日に3-4回サイコロが降られ、22日間カウントした結果、77回のサンプルを得ました。
| 面① | 面② | 面③ | 面④ | 面⑤ | 面⑥(視聴者プレゼント) | |
| ごきげんようのサイコロ | 1/7 | 1/7 | 1/7 | 1/7 | 1/7 | 2/7 |
| 普通のサイコロ | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 |
そこで、カイ2乗検定を用いて検定したのですが、5%の有意水準では、普通のサイコロと異なるとは結論できませんでした。
ところが、実際には番組では視聴者へのプレゼントが頻繁に出て番組を盛り上げるように『今日の当たり目』が他の目より2倍も出やすくなるように細工をしていました。
では、なぜ私の調査では有意差がでなかったのでしょう。
実は、上図のようなサイコロと普通のサイコロをカイ2乗検定で見分けるためには、
検出力とサンプル数に下図のような関係があるのです。
つまり、サンプル数が少ないと、(恣意的な)いんちきなサイコロと普通のサイコロとの違いを見逃してしまう可能性(第2種の誤り,β)が結構高いのです。
今回私が1月かけて得た77というサンプル数も、第2種の誤りをする可能性(β)が90%を上回る、かなり不十分なものだったのです。
この例では、第2種の誤り(β)をおこす危険性をほぼ0にする(検出力が100%)<打ち消し効果をだすためには>には、2500回以上もサイコロを振らないといけないのです。
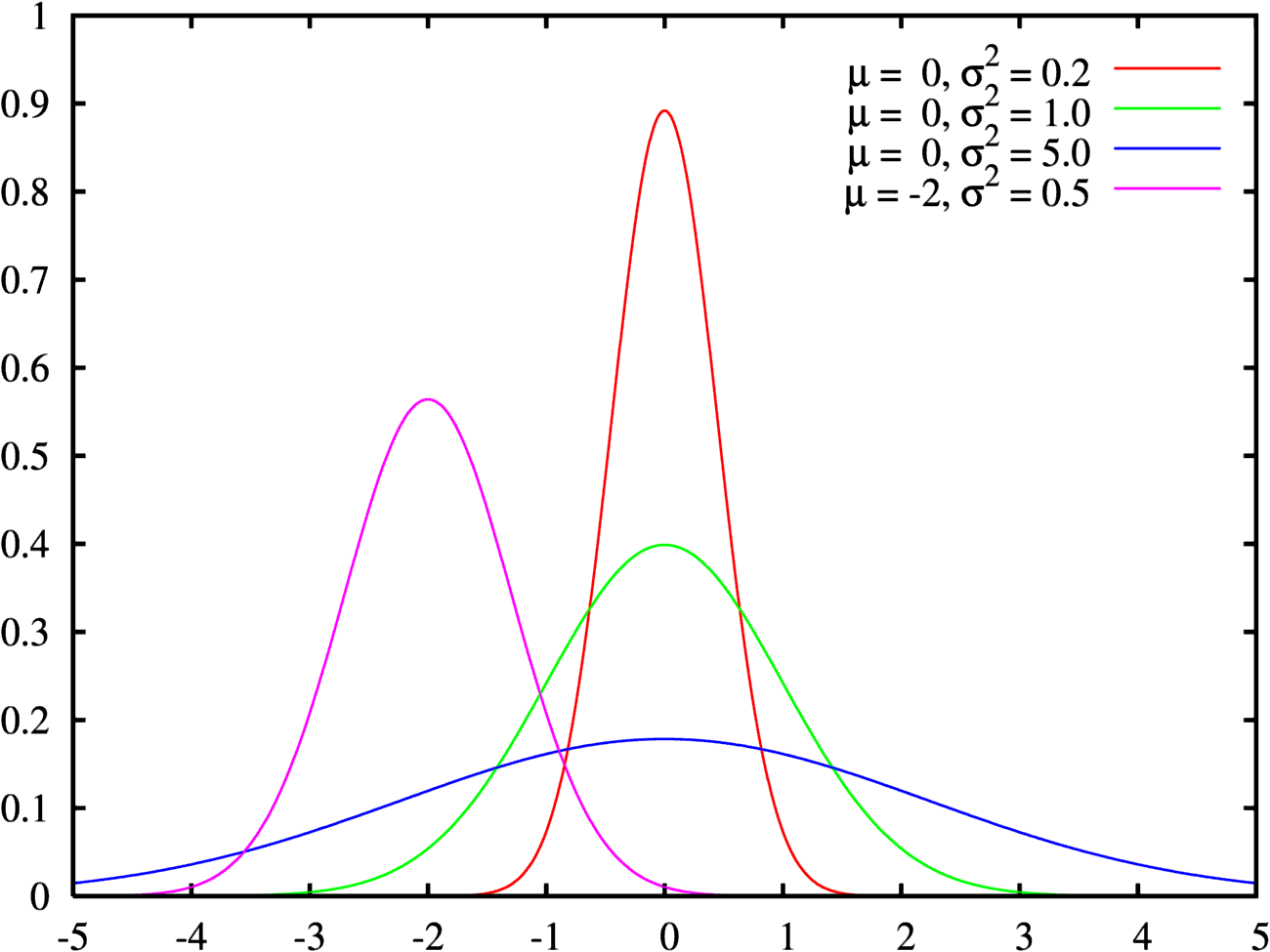
正規分布している集団の平均値を比較する場合の、t検定の検出力をみてみましょう。
ここでは、検出しようとしている平均値の差の大きさが、検出力に与える影響を見てみましょう。
両分布の平均値の差が小さく(d=0.5)分布は、分布曲線がかなり重なる。一方、より平均値の差が大きい(d=1.4)例では分布曲線の重なりは小さいです。※ dは平均値の差/分散です。
実際、上の例の検出力を様々なサンプル数で確かめてみると、d=1.4の場合にはサンプル数が20になると5%水準でがほぼ100%検出できるのに、d=0.5では160ものサンプルが必要になる。
このように母集団の平均値の差が、検出力に大きく影響することが分かりました。ですので、検出力を確かめるためにはあからじめ問題となる平均値の差を決めておく必要があある。
この差を決めるには、あなたがその検定をどのような目的で行っているのか立ち返って考えなくてはなりません。例えば、様々な処理がある生物のホルモン濃度に与える影響を調べる場合を想定しましょう。このホルモンはある器官に影響を与えますが、その効果はホルモン濃度がある閾値を越えないと表れません。よって問題となるのは、様々な処理がこの閾値を超えるほどにホルモン濃度を増加させるかであり、それ以下の差はとりあえず問題となりません。そこでこの場合、平常時のホルモン濃度(平均値あるいは信頼区間の上限)と閾値の差をd (=平均値の差/分散)=効果量として必要なサンプル数を求めましょう。この必要数は、計算によって求めることができます。
*正規分布(せいきぶんぷ、 Normal Distribution)は、ド・モアブルが二項分布の近似として発見した確率分布である。 その後、ラプラスやルジャンドル等の誤差や最小二乗法に関する研究を経て、ガウスの誤差論で詳細に論じられた。ガウス分布(Gaussian Distribution)とも呼ばれる。
検出力(1-β)は、上で述べたサンプル数(N)と真の差(d)以外に、有意水準(α)によっても変わります。これは検出力が、棄却率が有意水準以下になる割合であることを考えれば当然といえます。
観察された差が、本当に母集団に差があるために生じたと主張したい場合には、その現象が偶然生じている場合と見分けるために、有意水準を小さくすることで厳しい判断ができます。
だが一方で、母集団に差はなく、観察された差は全くの偶然に生じと主張したい場合もあります。この例は、特に観察された頻度分布を既知の分布(正規分布・ポワソン分布など)と比較する場合によく見られます。この際、サンプル数が非常に大きい場合を除いて、有意水準をいたずらに低く設定してしまうと、検出力が低下して母集団に差がないという結論を導きやすくなってしまいます。そこで有意水準を大きく(時には0.1以上に)設定した方が、かえって厳しい検定になります。
Co en, J (1988) Statistical Power Analysis for the Behavioral Sciences 2nd eds.,LawrenceErlbaum Asscociates, Publisher
ポイント1
サンプルサイズ
研究をデザインする場合には,パイロット研究などのデータに基づいて,一定のαエラー,Power=1‐βエラーの元で,必要なサンプルサイズを計算する必要がある。
ポイント2
αエラー
全く細工をしていない、すなわちインチキのない
サイコロを振った時は出目は1/6になるが、振り方が異なると、出目の数が、均一、すなわち1/6にならない。
このようなときに2つのサイコロの出目の確率が異なる可能性は高くなる。
( 恣意的なことが結果に影響を与えているということを、偶然が及ぼす結果への影響(これを危険率と言っている。)と比べて表したもの。
ポイント3
βエラー
サンプル数が少ないと、(恣意的な)いんちきなサイコロと普通のサイコロとの違いを見逃してしまう可能性(第2種の誤り,β)が結構高い。
という
補足
・学力の高い人が一度の入試でしくじって(学力が低いと誤認され)落ちてしまうのが第一種の誤り、
ポイント4
•その話のどこにもウソがないとしても、それさえ全体として偏っていて、偏った判断を誘うものです。
しかし、そうした誤判断の危険は、普通に情報を受け取っている人が、少ない情報だけで満足して「情報の裏を取る」ことをしないときにも、生じます。
ポイント5
検出力
•本当は正しいのに、偶然めったに起こらないことが起きてしまったために、その結論が間違っていると誤認してしまうこと
「第一種の誤り」
•