Javaプログラミング入門
6. 型変換
最終更新:
javatutorial
-
view
データ型の変換
プログラムを作成していると、整数の値を小数として扱いたい場合や
数値を文字列として表示したい場合など、現在のデータを別のデータ型に変換する必要が出てくることがあります。
例えば、商品の価格を計算する際、整数型(int)の「個数」と小数型(double)の「単価」を掛け算する際に、型の違いがでてきます。
また、ユーザーが入力した数値(int)を文字列(String)として保存したり、逆に文字列(String)として受け取った数値を計算に使うために数値型(int)へ変換したりすることもよくあります。
Javaには、こうした型の変換を行うための3つの方法があります。
数値を文字列として表示したい場合など、現在のデータを別のデータ型に変換する必要が出てくることがあります。
例えば、商品の価格を計算する際、整数型(int)の「個数」と小数型(double)の「単価」を掛け算する際に、型の違いがでてきます。
また、ユーザーが入力した数値(int)を文字列(String)として保存したり、逆に文字列(String)として受け取った数値を計算に使うために数値型(int)へ変換したりすることもよくあります。
Javaには、こうした型の変換を行うための3つの方法があります。
自動的に変わる型変換
小さいデータ型の値を、大きいデータ型の変数に代入すると、Javaが自動で型を変換します。
これは、小さい箱から大きい箱へ移すような感覚と同じで、小さい箱が大きい箱にそのまま収まるというイメージです。
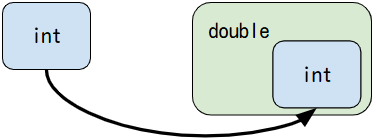
この仕組みは「自動型変換(ワイドニング変換)」と呼ばれ、特別な操作をしなくても自動的に処理されます。
例えば、int型(4バイト)の数値をdouble型(8バイト)の変数に代入すると、小数点を含む double 型の値に変わります。
この変換では、元の変数に代入されたデータの内容は変わらず、そのまま大きな型に収まるので安心です。
そのため、開発者は特別な記述をしなくても、安心して小さい型の値を大きい型に代入できます。
サンプル:TypeWideningConverter.java
これは、小さい箱から大きい箱へ移すような感覚と同じで、小さい箱が大きい箱にそのまま収まるというイメージです。

この仕組みは「自動型変換(ワイドニング変換)」と呼ばれ、特別な操作をしなくても自動的に処理されます。
例えば、int型(4バイト)の数値をdouble型(8バイト)の変数に代入すると、小数点を含む double 型の値に変わります。
この変換では、元の変数に代入されたデータの内容は変わらず、そのまま大きな型に収まるので安心です。
そのため、開発者は特別な記述をしなくても、安心して小さい型の値を大きい型に代入できます。
サンプル:TypeWideningConverter.java
- public class TypeWideningConverter {
- int num1 = 30;
- double num2 = num1;
- long num3 = num1;
- }
- }
-
実行結果
30.0
30手動で行う型変換
大きなデータ型の値を、小さなデータ型の変数に入れようとすると、コンパイルエラーになってしまいます。
- double num1 = 3.15;
- int num2 = 0;
- num2 = num1; // コンパイルエラー
エラーメッセージ
エラー: 不適合な型: 精度が失われる可能性があるdoubleからintへの変換
int num2 = num1;
^
エラー1個
これには、開発者が変換方法を明示的に指定する必要があります。
これは「強制的な型変換(ナローイング変換)」と呼ばれ、自動では行われません。
開発者がキャスト演算子という演算子を使うことで強制的にデータ型を変換させることが可能になります。
キャスト演算子は、変換したい値の前に(型名)をつけることで使用することができます。
これは「強制的な型変換(ナローイング変換)」と呼ばれ、自動では行われません。
開発者がキャスト演算子という演算子を使うことで強制的にデータ型を変換させることが可能になります。
キャスト演算子は、変換したい値の前に(型名)をつけることで使用することができます。
例
int num = (int) 9.75; // 9.75をint型に強制的に変換して変数numに代入する
double型は非常に広い範囲の数値を扱え、小数部分を持つことができます。
一方、int型は、小数を含むことができません。
一方、int型は、小数を含むことができません。
💡注意
そのため、double型の値をint型に変換するときは、小数部分が不要と判断され、切り捨てられます。
つまり、9.75をintに変換すると、小数点以下の.75 は削除され、結果は9になります。
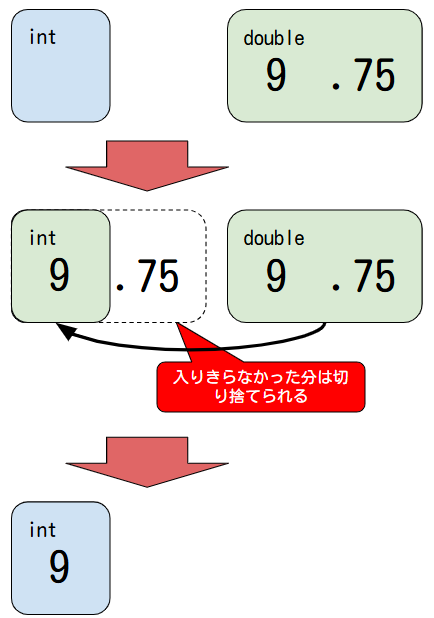
この変換では、データの一部が失われたり、意図しない結果になる可能性があるため注意が必要です。
そのため、明示的にキャストを行うことで、意図した変換であることをJavaに伝える必要があります。
サンプル:TypeNarrowingConverter.java
そのため、double型の値をint型に変換するときは、小数部分が不要と判断され、切り捨てられます。
つまり、9.75をintに変換すると、小数点以下の.75 は削除され、結果は9になります。

この変換では、データの一部が失われたり、意図しない結果になる可能性があるため注意が必要です。
そのため、明示的にキャストを行うことで、意図した変換であることをJavaに伝える必要があります。
サンプル:TypeNarrowingConverter.java
- public class TypeNarrowingConverter {
- double num1 = 9.75;
- int num2 = (int) num1;
- }
- }
-
出力結果
9計算時に起こる型変換
プログラムで数値の計算を行う際、演算子(+、-、*、/ など)を使って異なるデータ型の値を組み合わせることがあります。
本来、計算を正しく行うためには、左右のオペランドが同じデータ型であることが理想的です。
なぜなら、異なるデータ型の値をそのまま演算すると、小数が含まれる計算になったり、勝手に小数値を切り捨ててしまったりする問題が発生する可能性があるためです。
本来、計算を正しく行うためには、左右のオペランドが同じデータ型であることが理想的です。
なぜなら、異なるデータ型の値をそのまま演算すると、小数が含まれる計算になったり、勝手に小数値を切り捨ててしまったりする問題が発生する可能性があるためです。
しかし、1.53 / 2(double型 ÷ int型)のように、異なる型の値同士を計算することはよくあります。
このとき、毎回 1.53 / (double) 2 のように、手動で型変換を指定するのは面倒です。
このとき、毎回 1.53 / (double) 2 のように、手動で型変換を指定するのは面倒です。
そこで Javaには「左右の型が異なる場合、自動的に大きい型に統一する」 というルールがあります。
この仕組みにより、3.14 / 2の計算では、int型の2が自動的にdouble型に変換 され、
3.14 / 2.0 という形になって計算が行われます。
この仕組みにより、3.14 / 2の計算では、int型の2が自動的にdouble型に変換 され、
3.14 / 2.0 という形になって計算が行われます。
演算結果はint型以上になるルール
Javaにはもう一つ重要なルールがあります。
「演算の結果は int型以上のデータ型になる」 というルールです。
サンプル:AutoTypePromotion.java
「演算の結果は int型以上のデータ型になる」 というルールです。
サンプル:AutoTypePromotion.java
- public class AutoTypePromotion {
- short a = 10;
- byte b = 5;
- short result = a + b; // これはコンパイルエラー
- }
- }
-
実行結果
エラー: 不適合な型: 精度が失われる可能性があるintからshortへの変換
short result = a + b; // これはコンパイルエラー
^
エラー1個
この場合
short result = (short) (s1 + s2); // 明示的なキャストが必要
このように明示的な型変換が必要になりますので、気を付けるようにしましょう。
型変換の失敗
基本型のキャスト演算子を使うと、大きなデータ型の値を小さなデータ型の変数に代入できます。
ただし、数値型同士の変換以外では、キャスト演算子を使っても代入できません。
例えば、次のようなコードはコンパイルエラーになります。
例
ただし、数値型同士の変換以外では、キャスト演算子を使っても代入できません。
例えば、次のようなコードはコンパイルエラーになります。
例
int num = (int) "123"; // 文字列を数値にキャストしようとしているためエラー
boolean flg = (boolean) 5; // 数値を真偽値にキャストしようとしているためエラーコラム
文字列連結の効率化
1. +演算子による文字列連結
[+演算子]を使って文字列を連結すると、Javaコンパイラは最適化をします。
具体的には、文字列リテラルだけを連結する場合、コンパイル時に1つの文字列として扱われます。
これにより、実行時のパフォーマンスが向上し、通常はこの方法を推奨します。
[+演算子]を使って文字列を連結すると、Javaコンパイラは最適化をします。
具体的には、文字列リテラルだけを連結する場合、コンパイル時に1つの文字列として扱われます。
これにより、実行時のパフォーマンスが向上し、通常はこの方法を推奨します。
2. StringBuilderクラスを使用した文字列連結
StringBuilderは、可変長の文字列を効率的に扱うために設計されたクラスです。
特に、ループなどで文字列を頻繁に連結する場合、StringBuilderを使用することが推奨されます。
これは、StringBuilderを使うことで、内部的に文字列の再生成を避け、メモリの利用効率が良くなるためです。
StringBuilderは、可変長の文字列を効率的に扱うために設計されたクラスです。
特に、ループなどで文字列を頻繁に連結する場合、StringBuilderを使用することが推奨されます。
これは、StringBuilderを使うことで、内部的に文字列の再生成を避け、メモリの利用効率が良くなるためです。
3. StringBufferクラスを使用した文字列連結
StringBufferはスレッドセーフな文字列結合を行いたい場合に利用されます。
つまり、複数のスレッドから同時にアクセスされる可能性がある場合は
StringBufferを使った方が良いのですがその分、StringBuilderよりもパフォーマンスが劣ります。
StringBufferはスレッドセーフな文字列結合を行いたい場合に利用されます。
つまり、複数のスレッドから同時にアクセスされる可能性がある場合は
StringBufferを使った方が良いのですがその分、StringBuilderよりもパフォーマンスが劣ります。
具体的には、StringBufferのメソッドにはsynchronized修飾子が付与されており
スレッドの安全性を確保していますが、これによりオーバーヘッドが生じるため連結処理のスループットは低下します。
したがって、シングルスレッドの状況ではStringBuilderが推奨されますが
マルチスレッド環境では状況に応じてStringBufferを選べる柔軟性が必要になります。
スレッドの安全性を確保していますが、これによりオーバーヘッドが生じるため連結処理のスループットは低下します。
したがって、シングルスレッドの状況ではStringBuilderが推奨されますが
マルチスレッド環境では状況に応じてStringBufferを選べる柔軟性が必要になります。
参考資料:
https://zenn.dev/taiga533/articles/43fc599088bbbee39707
https://gabekore.org/javap-bytecode-plusoperator-stringbuilder
https://zenn.dev/taiga533/articles/43fc599088bbbee39707
https://gabekore.org/javap-bytecode-plusoperator-stringbuilder
[Amazon商品]









