まとめwiki
午後1&2対策
最終更新:
matowiki
-
view
データベーススペシャリスト試験の勉強法まとめは移転しました
情報処理試験まとめは、まとめwikiより情報処理試験関連情報だけ独立して情報を一新し別サイトに移転しました。
今後ともまとめwikiをよろしくお願いいたします。
移転先の情報処理技術者試験まとめwikiのトップページはこちら
Top > 情報処理試験まとめ > データベーススペシャリスト試験の勉強法まとめ > 午後1&2対策
今後ともまとめwikiをよろしくお願いいたします。
移転先の情報処理技術者試験まとめwikiのトップページはこちら
Top > 情報処理試験まとめ > データベーススペシャリスト試験の勉強法まとめ > 午後1&2対策
データベーススペシャリスト試験 午後1&2対策
目次
はじめに
はじめに
モバイル版が表示されてしまう人は画面最下部のPC版はこちらをクリックで見やすいページが表示されます。
主に問題を解答するためのパターンや定石、よくある考え方などをまとめてみました。
主に問題を解答するためのパターンや定石、よくある考え方などをまとめてみました。
関連ページ
- ITストラテジスト試験の勉強法まとめ
- データベーススペシャリスト試験の勉強法まとめ
- ネットワークスペシャリスト試験の勉強法まとめ
- プロジェクトマネージャ試験の勉強法まとめ
- 基本情報技術者試験の勉強法まとめ
- 応用情報技術者試験の勉強法まとめ
- 情報セキュリティスペシャリスト試験の勉強法まとめ
- 情報処理安全確保支援士試験の勉強法まとめ
お勧め参考書
参考書の種類について
参考書をいろいろみてみると、参考書は学習することをメインに作られた学習用参考書と、合格するためのテクニックを追求したようなテクニック習得用参考書の二種類にわかれていることがわかる。学習用の参考書はデータベースの基礎から記述されており、データベースのことを知らない人にもわかり易い作りになっている。テクニック習得用の参考書は基礎を習得している人向けに記述されており、合格するための情報や解答テクニックがメインとなっている。
学習用とテクニック用のわかりやすい区別の方法は、過去問の解説にどれだけページ数を割いているかだ。過去問の解説がない参考書はゼロから勉強するのに向いている学習用参考書と言える。過去問の解き方を解説している参考書はテクニック重視の参考書と言える。そして、それらの中間の参考書はデータベースに関する知識も解説しながら過去問も解説するというようなハイブリッド型になっている。
データベースでの開発経験の無い人は学習用参考書とテクニック習得用参考書を二冊、開発経験のある人はテクニック習得用参考書だけ利用するなどというように工夫をしよう。
ハイブリッド型は過去問の掲載数も少ないし、説明も中途半端なので避けたほうがいい。
学習用とテクニック用のわかりやすい区別の方法は、過去問の解説にどれだけページ数を割いているかだ。過去問の解説がない参考書はゼロから勉強するのに向いている学習用参考書と言える。過去問の解き方を解説している参考書はテクニック重視の参考書と言える。そして、それらの中間の参考書はデータベースに関する知識も解説しながら過去問も解説するというようなハイブリッド型になっている。
データベースでの開発経験の無い人は学習用参考書とテクニック習得用参考書を二冊、開発経験のある人はテクニック習得用参考書だけ利用するなどというように工夫をしよう。
ハイブリッド型は過去問の掲載数も少ないし、説明も中途半端なので避けたほうがいい。
学習用参考書
データベースの業務経験が無い人は、まずは参考書を利用してデータベースに関する基礎知識から学習するのがお勧め。データベースの学習のための本はいろいろあるが、やはり資格試験で必要とされている知識はある程度決まっているので、資格試験用に記述された参考書での学習がお勧め。
2017年学習用参考書一覧
テクニック習得用参考書
実務経験がある人も無い人も絶対に購入すべき参考書がテクニック用参考書だ。情報処理教科書は自分も実際に利用してとても重宝したのでおすすめできる。特に午後1、午後2の解説や解答方法の具体的なテクニックが記述されており、これを読むことで解答能力が確実にUPする。
データベーススペシャリスト試験における独特の解答の言い回しもしっかり記述されており、これを暗記するだけで確実に回答欄を埋めることができる。
テクニックだけでなく正規化、データモデリングに関する解説もしっかり記述されているので、データベースの構築経験やクエリを書ける人がうろ覚えにしている知識も再確認できる。
さらに多くの過去問解説をWEBからダウンロードして入手することができる。この解説は一つの問題に対して数ページ、場合によっては10ページ近く解説がされており購入する価値は高い。
過去問はこの参考書で網羅されているので、これを一冊購入すればわざわざ午後1、午後2用の過去問題集も買う必要はないのでお勧めだ。
データベーススペシャリスト試験における独特の解答の言い回しもしっかり記述されており、これを暗記するだけで確実に回答欄を埋めることができる。
テクニックだけでなく正規化、データモデリングに関する解説もしっかり記述されているので、データベースの構築経験やクエリを書ける人がうろ覚えにしている知識も再確認できる。
さらに多くの過去問解説をWEBからダウンロードして入手することができる。この解説は一つの問題に対して数ページ、場合によっては10ページ近く解説がされており購入する価値は高い。
過去問はこの参考書で網羅されているので、これを一冊購入すればわざわざ午後1、午後2用の過去問題集も買う必要はないのでお勧めだ。
2017年テクニック習得用参考書(情報処理教科書が最もおすすめ、絶対に購入すべし)
解答時のテクニック 午後1
時間配分を守る
午後1はとにかく時間との勝負になる。最初のほうで少し戸惑って時間が取られると、それでパニックになってしまい、その後がまったく回答できなくなってしまうことがあるので、とにかく慎重に進めていく事が大事だ。
テクニックとしては、設問ごとの時間配分をしておくこと。例えば、午後1なら設問1への解答時間を40分と決めておく。そして40分経ったらもう強制的に次の設問に進むようにしよう。できれば同じ設問中でも時間を設定し、一つの問に対して13分というように設定しておく。それを過ぎたら途中でも次の問題に進むようにしよう。
できなかった問題は後からの残り時間で見直せばいいし、時間がなかったらそれは仕方がないと思って諦めよう。とにかく一つの問題に時間をとられると点数が稼げなくなってしまうから、時間配分を決めてある程度割り切ってどんどん先に進むのも重要だ。
テクニックとしては、設問ごとの時間配分をしておくこと。例えば、午後1なら設問1への解答時間を40分と決めておく。そして40分経ったらもう強制的に次の設問に進むようにしよう。できれば同じ設問中でも時間を設定し、一つの問に対して13分というように設定しておく。それを過ぎたら途中でも次の問題に進むようにしよう。
できなかった問題は後からの残り時間で見直せばいいし、時間がなかったらそれは仕方がないと思って諦めよう。とにかく一つの問題に時間をとられると点数が稼げなくなってしまうから、時間配分を決めてある程度割り切ってどんどん先に進むのも重要だ。
解答時のテクニック 午後2
設問の構成を最初に調べる
問題の構成は、おおむね最初に企業の業種や組織、業務プロセス、システムのテーブル構造を文章で説明し、その後に業務の改善要望が記述されているパターンが多い。ほとんどの問題で「現状の業務やシステムの説明→新しい要望の説明」となっていて区切りがつけられている。設問も現状の業務の解説と改善要望は分けられているので、「現状の業務」の説明まで読んだらその部分をまず解答して現状のテーブル構造を確定してしまおう。それから新しい要望に取りかかったほうが効率がいい。
問題文を読みながら会社の仕組み、ビジネスロジックなどを簡単な図でまとめる
午後1にも午後2にも言えることだが、その会社の組織やビジネスロジックを理解することはとても重要だ。そのため問題文を読みながらその組織の組織図、伝票の作られ方、商品の配送方法などを簡単にメモしながら問題文を読んでいくようにすると、すんなり組織を覚えてることができる。
例えば、「本社があり、商圏をいくつかの地域に分け、そこに複数の支社がある。配送センターは地域に一つだけある。営業担当は同じ地域の複数の支社に所属することがある。」みたいな記述がある場合には、以下のように簡単な図を作ってまとめる。こうすると頭の中で簡単に整理できる。
例えば、「本社があり、商圏をいくつかの地域に分け、そこに複数の支社がある。配送センターは地域に一つだけある。営業担当は同じ地域の複数の支社に所属することがある。」みたいな記述がある場合には、以下のように簡単な図を作ってまとめる。こうすると頭の中で簡単に整理できる。
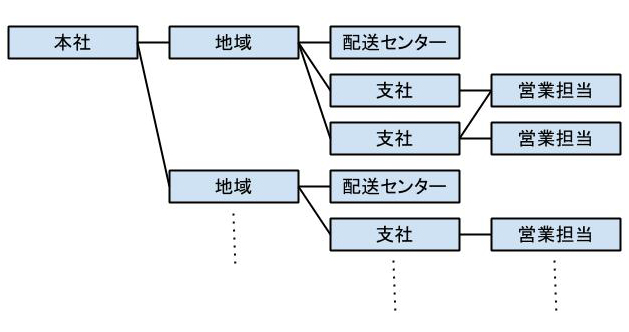
問題文とER図、関係スキーマなどの図表を見比べて確認する
データベーススペシャリストの午後2問題は業務プロセスを文章で説明し、そしてテーブル構造を答えさせようとしている。逆に言えばテーブル構造を文章で説明していることになる。
説明はおおむねテーブルごとに、それぞれのテーブルについて解説している。なので、もし問題文に関係スキーマ(テーブル)、概念データモデル(ER図)が図や表として記述されているようなら、問題文とそれらの図や表をページをめくり行き来し、問題文中のテーブルの説明と図や表中に記述されているテーブルを比較し記述内容を確認するようにする。
例えば「企業には複数の支社があり支社コードで識別される」などという説明があれば、おそらく支社テーブルが存在し支社コードが主キーとなっているであろうことがわかる。そしたら関係スキーマやER図を調べて支社テーブルを探して、テーブルがあることの確認と、支社コードが候補キーまたし主キーとして存在していることを確認する。もし支社テーブルに該当するテーブルがなかったり、そのテーブルに支社コード属性がない場合、そのテーブルや属性を答えさせる設問が出る可能性が高い。
説明はおおむねテーブルごとに、それぞれのテーブルについて解説している。なので、もし問題文に関係スキーマ(テーブル)、概念データモデル(ER図)が図や表として記述されているようなら、問題文とそれらの図や表をページをめくり行き来し、問題文中のテーブルの説明と図や表中に記述されているテーブルを比較し記述内容を確認するようにする。
例えば「企業には複数の支社があり支社コードで識別される」などという説明があれば、おそらく支社テーブルが存在し支社コードが主キーとなっているであろうことがわかる。そしたら関係スキーマやER図を調べて支社テーブルを探して、テーブルがあることの確認と、支社コードが候補キーまたし主キーとして存在していることを確認する。もし支社テーブルに該当するテーブルがなかったり、そのテーブルに支社コード属性がない場合、そのテーブルや属性を答えさせる設問が出る可能性が高い。
問題文へのマーキング
上記のように問題文と関係スキーマやER図を行き来し、一つ一つ確認していくとおかしな記述があったり、該当するテーブルがなかったりする場合がある。
テーブルがない場合はひょっとしたら虫食い問題になっている可能性があるので、その部分は非常に重要だ。とりあえず疑問に思いながらも問題文を読み進むわけだが、読み進めるうちに忘れてしまう可能性があるので疑問を感じた部分に下線を引いて欄外に「はてなマーク」を書いておこう。可能なら欄外に「支社テーブルがあるはず?」「主キーとして支社コードがない?」などとメモしておく。こうすると、あとで簡単に見直すことができる。
また読み進めるとロジック的におかしいなと思われる部分を見つけることもある。例えば将来的に商品の値段を変更する可能性があるのに、その商品の値段の履歴を残すようなテーブル構造になっていないような場合である。これだと商品の値段を変更すると過去の売上げの値段すべてが変更されて金額がおかしくなってしまう。こういうものを見かけたときも下線を引いて「価格変更履歴テーブルは?」などと記述しておく。
テーブルがない場合はひょっとしたら虫食い問題になっている可能性があるので、その部分は非常に重要だ。とりあえず疑問に思いながらも問題文を読み進むわけだが、読み進めるうちに忘れてしまう可能性があるので疑問を感じた部分に下線を引いて欄外に「はてなマーク」を書いておこう。可能なら欄外に「支社テーブルがあるはず?」「主キーとして支社コードがない?」などとメモしておく。こうすると、あとで簡単に見直すことができる。
また読み進めるとロジック的におかしいなと思われる部分を見つけることもある。例えば将来的に商品の値段を変更する可能性があるのに、その商品の値段の履歴を残すようなテーブル構造になっていないような場合である。これだと商品の値段を変更すると過去の売上げの値段すべてが変更されて金額がおかしくなってしまう。こういうものを見かけたときも下線を引いて「価格変更履歴テーブルは?」などと記述しておく。
復習方法
情報処理教科書の解説を読み、具体的に回答するテクニックを学ぶこと。情報処理教科書には、解答を導き出す方法が記述されているので、もういちど最初から解答するようなイメージで問題文と解説を見比べて、自分はなぜその問題文のヒントに気がつかなかったのか、なぜそのような手法などに気がつかなかったのか等を学んでいくようにしよう。
特にこのwikiで記述している解答パターンはかなり役立つと思うので理解して暗記しておいて欲しい。
特にこのwikiで記述している解答パターンはかなり役立つと思うので理解して暗記しておいて欲しい。
解答パターン 午後1&午後2
問題文を読んでいて疑問に思うパターン
問題文を読んでいると、これはどうするの?こうでなければおかしいと疑問に感じることがある。その多くは下記のパターンのいずれかに当てはまることが多いので、これらのパターンを覚えておくと何を答えさせようとしているかを理解しやすくなる。
問題文に記述されている属性やテーブルがない
よくあるパターンのNo1。問題文とER図や関係スキーマを確認し、該当するテーブルや属性があるかどうかを探す。無ければ虫食い問題になっている可能性が高い。
履歴が残せない
例えば商品マスタに商品金額が記述されているが、売上げ伝票(売上げ明細)に個別の商品金額を記録できないようなパターン。この場合、商品マスタの金額を変更してしまうと過去に売り上げた伝票の商品金額もすべて変更されてしまうことになるので問題になる。売上げ時の金額を残せないというのは問題にされる可能性がある。
正規化されていない
正規化されていないと同じ情報を重複して登録してしまう可能性がでてくる。例えば商品を販売するたびに売上げ伝票に顧客の名前、住所、電話番号を登録するような場合だ。この場合、顧客の電話番号が変わったりしたとき、過去の売上げ時に入力された顧客情報と整合性がとれなくなるので問題になる。
属性の変更を考慮していない
営業部員の売上げの成績は保存されるが、売上げ時の営業部員が所属していた支社の情報が記録されないパターン。例えば従業員マスタで営業部員と所属する支社の紐付けがされているとする。そうすれば従業員と支社の紐付けがされているので、営業部員の売上げ成績から支社別の売上げ成績も導きだすことができる。
しかし会社には異動が付きもの。もし従業員マスタで従業員が異動し現在の所属先の支社に変更されてしまったら、その従業員の過去の売上げも新しい支社の売上げとして計算されてしまうことになる。このように属性が変更されることを考慮しないと、あとから集計したときに値が変化してしまうことがあるので注意が必要である。
従業員と支社の関係以外にも、商品と商品価格、商品と商品の仕入れ先など、その時々によって変更する可能性があるものをマスタ的に登録していると不整合が生じる可能性があるので、そのあたりを見たときに疑問を感じてチェックしておくことが重要。
しかし会社には異動が付きもの。もし従業員マスタで従業員が異動し現在の所属先の支社に変更されてしまったら、その従業員の過去の売上げも新しい支社の売上げとして計算されてしまうことになる。このように属性が変更されることを考慮しないと、あとから集計したときに値が変化してしまうことがあるので注意が必要である。
従業員と支社の関係以外にも、商品と商品価格、商品と商品の仕入れ先など、その時々によって変更する可能性があるものをマスタ的に登録していると不整合が生じる可能性があるので、そのあたりを見たときに疑問を感じてチェックしておくことが重要。
わざと冗長に記録させるパターン
集計などを早く行うために売上げ伝票に売上げ詳細の合計金額などを記録させるパターン。通常、売上げ伝票ごとの金額は売上げ詳細テーブルに記載されている商品金額×販売数の合計を計算して求めるが、詳細が多くなると計算に時間がかかってしまう場合がある。この場合、売上伝票に合計金額を保存しておけば売上げ詳細テーブルの演算を行わなくて済むので計算が早く済む。しかしご発注などのため売上げ詳細テーブルの金額や商品販売数が修正されると合計金額が変わってしまう。そうなると売上げ伝票テーブルに記録した合計金額と数字のズレがでてしまうが、これを考慮したロジックになっていないと問題が発生してしまう。問題文中にそれら整合性をどうするかの説明がないと疑問に感じなければならないパターンだ。
テーブルの新規作成パターン
午後2の問題を解いていると、ビジネスロジックの改良に伴い、既存のテーブルに新たにテーブルを追加して設計を変更させようとする設問がある。テーブルはだいたい以下のような理由で新たに追加される可能性が高い。このパターンを理解しておくと何を答えさせようとしている問題なのか想像しやすくなるので覚えておくと良い。
他のデータを束ねる
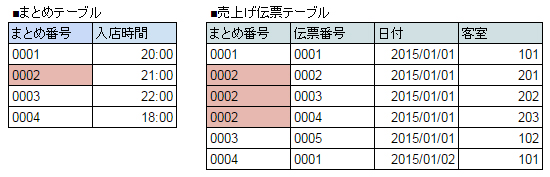
新たに他のデータをまとめるためのテーブルを新規作成するパターン。例えばカラオケボックスで、通常は一部屋に対して1枚の売上伝票で別々に精算しなければならないものを、グループで複数の部屋を借りたときにまとめて支払いたいというようなパターンだ。飲食店で席が別々になってしまったグループの複数の伝票をまとめて支払いたいなどというようなパターンにも当てはまる。
この場合には、例えば下記の画像のように新しく「まとめテーブル」などを新規作成し、その「まとめ番号」などを売上げ伝票テーブルに新たに作成したまとめ番号属性に保存することで実現する。こうすると、これまで客室ごとに一枚の伝票だったものが一つのまとめ番号で紐付けされるので複数の部屋でもまとめて支払いが可能になる。
この場合には、例えば下記の画像のように新しく「まとめテーブル」などを新規作成し、その「まとめ番号」などを売上げ伝票テーブルに新たに作成したまとめ番号属性に保存することで実現する。こうすると、これまで客室ごとに一枚の伝票だったものが一つのまとめ番号で紐付けされるので複数の部屋でもまとめて支払いが可能になる。
連関テーブル
業務プロセスの変更で、テーブルのリレーションシップが1対多から、多対多になってしまいそれを表現するために連関テーブルを新規作成するパターン。例えば支社と従業員の関係で、これまで従業員は一つの支社にしか所属していなかったのに、業務プロセス等の変更で従業員が複数の支社に所属するように変更され、支社-従業員が1対多の関係だったものが多対多になってしまったパターンなどが該当する。
この場合、多対多の関係を表現するために連関テーフルを新規で作成することで対応する。
この場合、多対多の関係を表現するために連関テーフルを新規で作成することで対応する。
マスタテーブルとして追加する
業務プロセスの変更で、新たなマスタテーブルを追加しなければならなくなるパターン。例えば飲食店でこれまで「商品」だけだったものを、料理、ドリンク、セット定食などというように商品カテゴリで商品を分ける必要があり、商品区分マスタなどとして新たなテーブルを作成するパターンなどだ。
商品区分マスタに区分コード、区分名などの属性を作成し、商品テーブルに新たに商品区分属性を作成して区分コードを保存することで対応する。
商品区分マスタに区分コード、区分名などの属性を作成し、商品テーブルに新たに商品区分属性を作成して区分コードを保存することで対応する。
サブタイプの追加
業務プロセスの変更で、新たなサブタイプを作成するパターン。例えば食料品メーカで使用する野菜に関して、これまで通常の野菜と有機野菜のみの区別だったものに、輸入野菜という新たな分類となる野菜を使用するために、輸入野菜を管理する新たな属性を追加する必要になるパターンなどだ。
この他にも、製造業で自社部品だけでなく他社製造部品も利用するようになり、部品を自社と他社で別の属性で管理する必要になったというパターンや、飲食店で同じレシピの料理だけどセット商品として提供する場合と単品で提供する場合によって異なる属性で管理したいというパターンなどがある。
主に「同じ商品」なんだけど、製造元が異なったり、提供先や提供方法が異なるため、その場合だけ別々に管理したいというような場合に新たなサブタイプとしてテーブルを新規追加することが必要になるパターンである。
この他にも、製造業で自社部品だけでなく他社製造部品も利用するようになり、部品を自社と他社で別の属性で管理する必要になったというパターンや、飲食店で同じレシピの料理だけどセット商品として提供する場合と単品で提供する場合によって異なる属性で管理したいというパターンなどがある。
主に「同じ商品」なんだけど、製造元が異なったり、提供先や提供方法が異なるため、その場合だけ別々に管理したいというような場合に新たなサブタイプとしてテーブルを新規追加することが必要になるパターンである。
テーブルへのフィールド新規追加パターン
午後2の問題を解いていると、ビジネスロジックの改良に伴い、既存のテーブルに新たにフィールドを追加して設計を変更させようとする設問がある。フィールドはだいたい以下のような理由で新たに追加される可能性が高い。このパターンを理解しておくと何を答えさせようとしている問題なのか想像しやすくなるので覚えておくと良い。
行の属性を表現するための属性の追加
商品マスタなどで、その商品に関する属性を追加させるパターン。例えば飲食店で提供する料理を飲み物と料理に区別して売上げを集計したいとか、ホテルの部屋を喫煙室と禁煙室に区別して予約を受け付けたいというパターンだ。
この場合、料理マスタに「商品区分」などの属性を追加したり、ホテルの部屋を禁煙と喫煙に区別するために部屋マスタに「喫煙区分」を追加するなどが該当する。
この場合、料理マスタに「商品区分」などの属性を追加したり、ホテルの部屋を禁煙と喫煙に区別するために部屋マスタに「喫煙区分」を追加するなどが該当する。
集計行を追加するための属性追加
部品マスタなどで、その部品の在庫数を保存する属性を追加させるパターン。例えば製造メーカでこれまでは半製品の在庫を記録していなかったが業務効率改善のために半製品の在庫数を保存する必要がでてきたなどのパターンだ。
この場合、半製品マスタに「在庫数」などの属性を追加するなどが該当する。
この場合、半製品マスタに「在庫数」などの属性を追加するなどが該当する。
履歴を残すための属性追加
商品マスタなどで、その商品の価格の履歴を保存する属性を追加させるパターン。例えば製造メーカでこれまで商品の値段は同じであったがこれからは頻繁に価格を反映させたいので履歴を残しておく必要があるとか、飲食店で一定期間だけ料理を特別価格として安く販売したいので過去の販売金額の履歴を残したいとか、従業員の過去の所属部署を履歴として残しておきたいというパターンだ。
この場合、商品マスタに「販売開始日」などの属性を追加したり、料理マスタに「販売開始日」などの属性を追加したり、社員マスタに「配属日」などの属性を追加することなどが該当する。
このパターンは、これまで普通だったただの縦横の表に、突然時系列という時間の流れという概念を取り入れなければならないので発想の転換が必要になり難易度が高い。
このパターンでは例えば商品価格では、商品の価格を変更するたびに販売開始日を設定して新たに行を作ることになる。従って、例えば{商品コード、販売開始日}が候補キーになる。販売開始日を設定することで、例えば下記の例だと商品コード0001の製品は、2015年01月01日から2015年01月31日まで300円で販売していたことがわかるということになる。
またこのパターンでは、将来に対する価格変更の予約のようなことも可能になる。例えば、2015年2月1日から新価格で販売することを事前登録しておくということも可能。
この場合、商品マスタに「販売開始日」などの属性を追加したり、料理マスタに「販売開始日」などの属性を追加したり、社員マスタに「配属日」などの属性を追加することなどが該当する。
このパターンは、これまで普通だったただの縦横の表に、突然時系列という時間の流れという概念を取り入れなければならないので発想の転換が必要になり難易度が高い。
このパターンでは例えば商品価格では、商品の価格を変更するたびに販売開始日を設定して新たに行を作ることになる。従って、例えば{商品コード、販売開始日}が候補キーになる。販売開始日を設定することで、例えば下記の例だと商品コード0001の製品は、2015年01月01日から2015年01月31日まで300円で販売していたことがわかるということになる。
またこのパターンでは、将来に対する価格変更の予約のようなことも可能になる。例えば、2015年2月1日から新価格で販売することを事前登録しておくということも可能。

正規化に関する解答パターン
正規化に関する解答パターンも暗記しておくことが望ましい。これらは必ず出題されるので確実に答えられるようにしておこう。
詳細については情報処理教科書 データベーススペシャリストに記述されているので、その説明を読んで理解することが必要。以下は暗記用のチェックシート代わりに。
詳細については情報処理教科書 データベーススペシャリストに記述されているので、その説明を読んで理解することが必要。以下は暗記用のチェックシート代わりに。
第一正規形でない理由(正規化されていない理由)
- 属性○○は属性△△の集合であり単一値ではないため
- 属性○○が繰り返し項目であり単一値ではないため
第一正規形の理由
- すべての属性が単一値で、候補キーA、Bの一部であるBに非キー属性のCが部分関数従属するため
- 非キー属性であるCが候補キーの一部であるBに関数従属し、候補キーに完全関数従属していないから
- 非キー属性であるCが候補キーの部分集合{A、B}に関数従属し、候補キーに完全関数従属していないから
第二正規形の理由
- すべての属性が単一値で、候補キーからの部分関数従属がなく、推移的関数従属性A→B→Cがあるため
第三正規形の理由
- すべての属性が単一値で、候補キーからの部分関数従属がなく、候補キーからの推移的関数従属性もないため
ボイスコッド正規形の理由
- すべての属性が単一値で、すべての関数従属性が、自明であるか、候補キーのみを決定項として与えられている
第四正規形の理由
- すべての属性が単一値で、すべての多値従属性が、自明であるか、候補キーのみを決定項として与えられている
第五正規形の理由
- すべての属性が単一値で、すべての結合従属性が、自明であるか、候補キーのみを決定項として与えられている
正規化されていないと発生する可能性のある問題
- ○○(例:商品)を事前にマスタとして登録できない
- 属性○○が冗長になる
- 属性○○を重複して登録するので不整合が生じる
- 属性○○が冗長であるため、これらを同時に修正しないと整合性が失われる
- 属性○○の情報が特定の一行にしか存在しない場合、その行を削除するとその属性の情報が永遠に失われる
結合に関する解答パターン
集計時に外部結合する理由
- すべての○○(例:店舗)に対して△△(例:売上げ)が存在するとは限らないが、すべての○○ごとに集計して結果を出力するから
コメント
&trackback()
