このページについて
このページは N.こづけ によって創作されている人工言語「マジューユ」に関する情報をまとめているものです。なお、全体的に書きかけです。ご了承下さい。
単語を眺めたい方はこちら→マジューユ単語集
質問箱を見たい方はこちら→Q&A
発見済み課題一覧はこちら→改善すべき事項
ベースの配置法等はこちら→配置パターン
コメントしたい方はこちら→コメント欄
制作者のどうでも良い呟き→制作者のつぶやき
単語を眺めたい方はこちら→マジューユ単語集
質問箱を見たい方はこちら→Q&A
発見済み課題一覧はこちら→改善すべき事項
ベースの配置法等はこちら→配置パターン
コメントしたい方はこちら→コメント欄
制作者のどうでも良い呟き→制作者のつぶやき
英語バージョンは以下のリンクから
If you want to see the English version of the explanation, click below.
https://w.atwiki.jp/constlangmajuuyuen/pages/1.html
If you want to see the English version of the explanation, click below.
https://w.atwiki.jp/constlangmajuuyuen/pages/1.html
目次
マジューユ概要
人工言語マジューユは「学びやすい言語をつくる」というコンセプトの基につくられている国際補助言語です。
- 特徴
ベースと呼ばれる簡便な表語文字を組み合わせて単語が作られており、これにより視覚的にわかりやすい単語を比較的容易に作ることができます。
- 制作者による解説動画
文字
マジューユの単語はベースと呼ばれる簡易的な表語文字の組み合わせで表されます。
以下にベース一覧を示します。なおベースは今後増える可能性があります。
以下にベース一覧を示します。なおベースは今後増える可能性があります。
- 表語ベース(単語用)
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
- 表音ベース(文法用)
 |
 |
 |
 |
 |
 |
・ベースの縦横の長さ
造語ルールにおける区画計算のため、各ベースは縦と横の長さが決められています。
以下にその値を示します。
ここでは、後述の収容区画の一目盛りの長さを1とします。
以下にその値を示します。
ここでは、後述の収容区画の一目盛りの長さを1とします。
以下、 (横 , 縦) という順で表記します。
- 表語ベースの縦横値 (横,縦)
| |
|
|
|
|
|
(2,2) (2,2) (3,1) (2,2) (2,2) (1.5,3)
|
|
|
|
|
|
(2,2) (1.5,3) (2,2) (3,1) (3,1) (3,1)
|
|
|
|
|
(2,2) (3,1.5) (2,2) (1,1) (2,2)
表音ベースの縦横値 (横,縦)
|
|
(2,3) (2,2)
なお、表音ベースのうち、品詞区別に作用するベースは区画計算に寄与しないため、縦横の値はありません。
- 特殊なベース

空白ベース
これは、音だけで形のないベースです。
主に配置を整えるために使われます。
主に配置を整えるために使われます。
例えば、
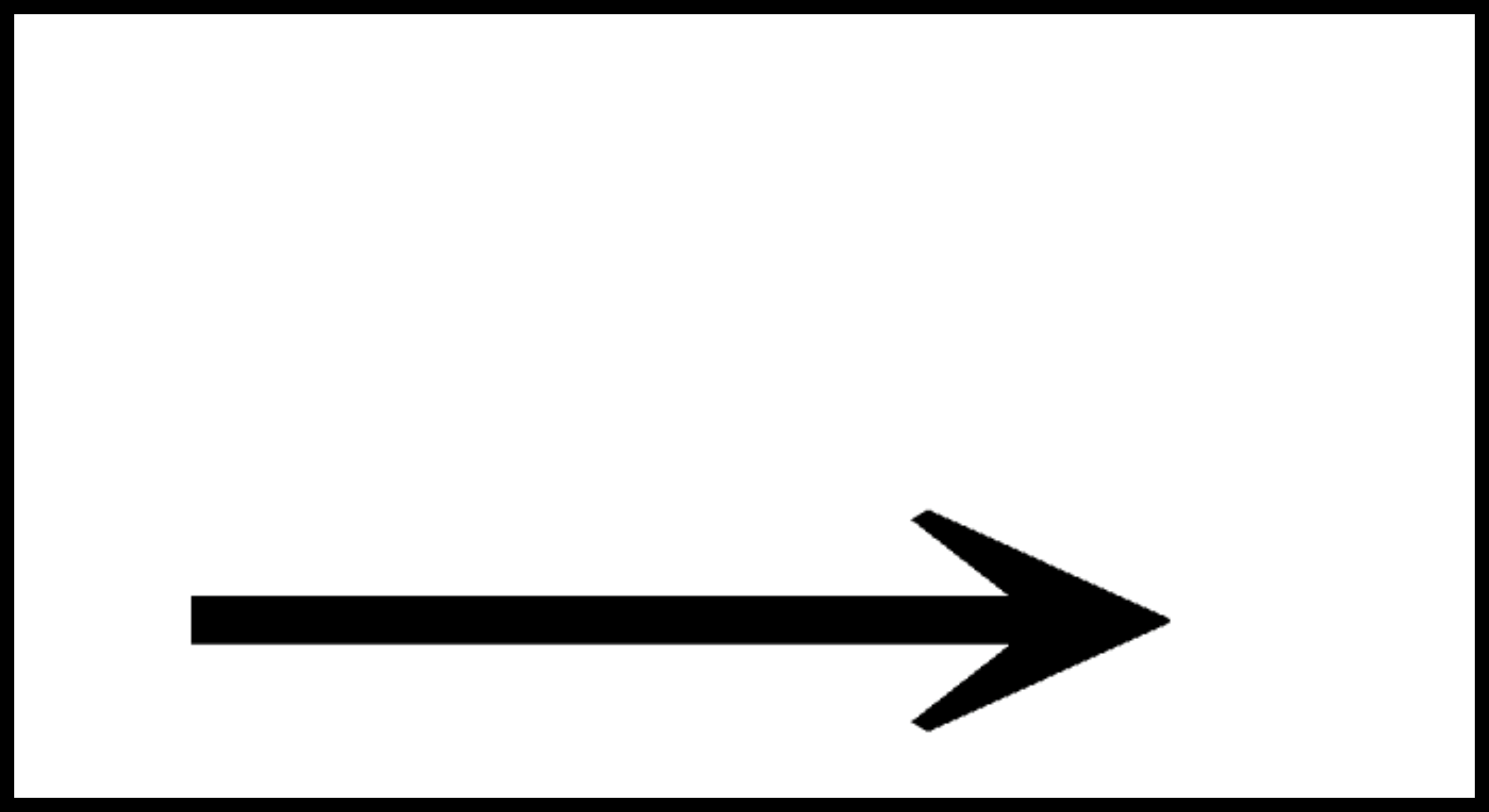
は上側に空白が有ることにより→が下側に、

は上側に空白が有ることにより→が下側に、
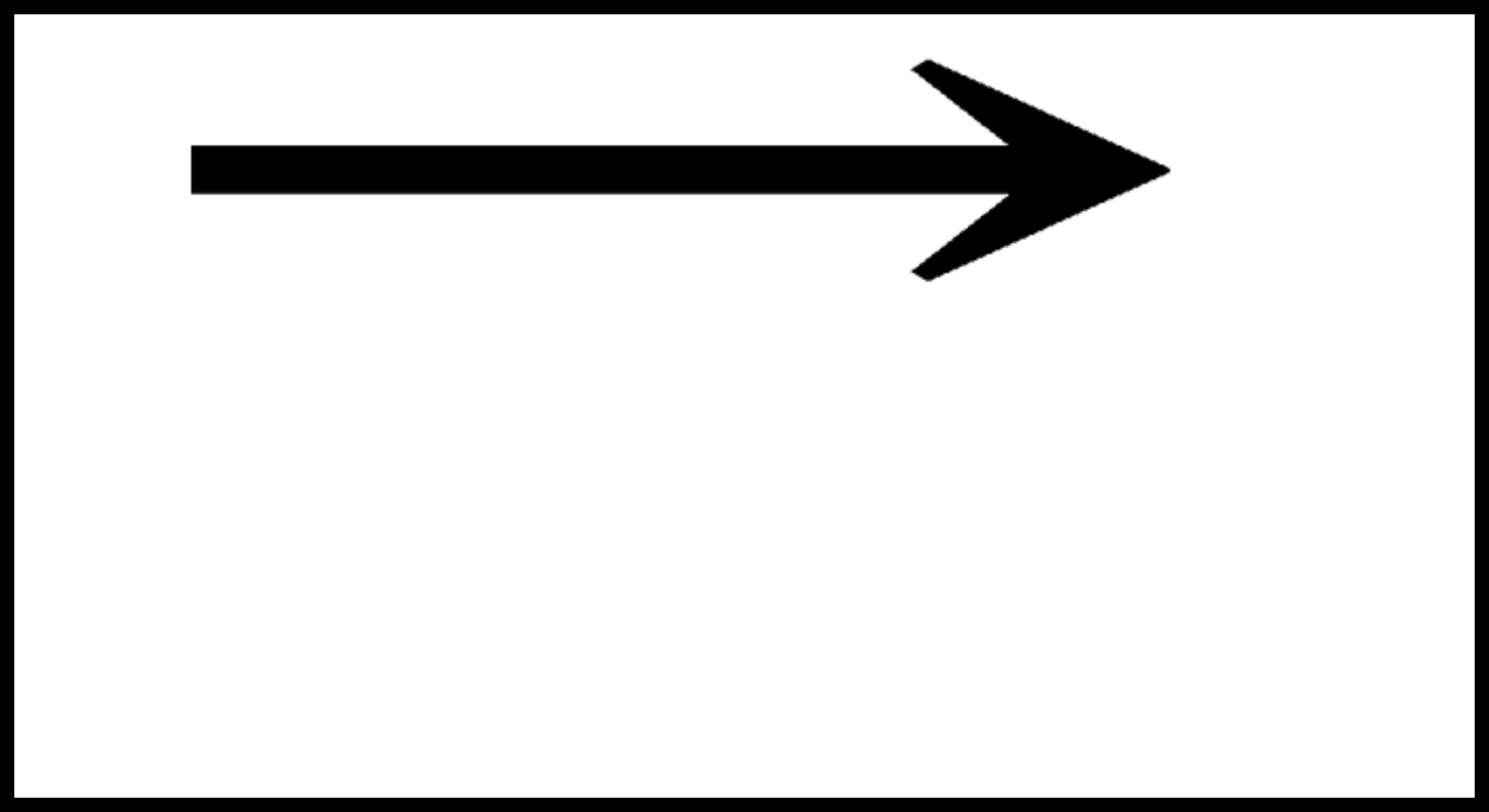
は下側に空白が有ることにより→が上側に表示されます。
視覚的にはこれらの違いはわかりやすいですが、口頭での区別が難しいので音があります(暫定の音は「ム」)。
下の配置パターン表に沿って配置され、形は持ちませんが配置に影響を及ぼすものです。
下の配置パターン表に沿って配置され、形は持ちませんが配置に影響を及ぼすものです。
・造語ルール
限界収容区画
一文字は上記の区画(縦6×横7)に収まるように配置しなければなりません。
文字全体の縦の値の和が6以下 かつ 横の値の和が7以下 であれば良いということです。
この前提をクリアしていれば、その文字は全体を区画の限界まで拡大して表示されます(可読性を高めるため)。
文字全体の縦の値の和が6以下 かつ 横の値の和が7以下 であれば良いということです。
この前提をクリアしていれば、その文字は全体を区画の限界まで拡大して表示されます(可読性を高めるため)。
最大ベース数
一文字に使用できるベース数は最大7つまでです。
これ以上となると、配置パターンも多くなり過ぎてしまいますし、発音も冗長になります(現時点で冗長ですけどねw)。
これは、インが起きているベースのアウトベースも等しく1個とカウントされます。
これ以上となると、配置パターンも多くなり過ぎてしまいますし、発音も冗長になります(現時点で冗長ですけどねw)。
これは、インが起きているベースのアウトベースも等しく1個とカウントされます。
ベースの方向
ベースには方向があるものがあります。
方向を口頭で区別するために、方向の違う同種のベースは異なる発音を持ちます。
方向を口頭で区別するために、方向の違う同種のベースは異なる発音を持ちます。
現時点では2方向もしくは4方向のものしかありませんが、
将来的に8方向になる可能性があったりします。
将来的に8方向になる可能性があったりします。
方向があることにより大分自由度の高い造語が出来るのでこれはマジューユに欠かせない要素です。
次の発音の項で方向を描写したベースを示します。
発音
発音に関しても今後変更する可能性が高いので、暫定のものとして受け取っていただけると幸いです。
まず、詳しいことは後にして、字形と発音を示します。
以下では最新のバージョンが現在の基準だと思って下さい。
過去のものを消さないのは、編集時点でページ内の単語表記が統一されていないことが多いのと、自分用のリファレンスとして使うからです。
小さな変化はVerは変えずにしれっと内容を変更しますので、大きな変化がなければVerは変わりません。
一段目はVer.1です。 例:レ レー
二段目はVer.2です。 例: nu na
以下では最新のバージョンが現在の基準だと思って下さい。
過去のものを消さないのは、編集時点でページ内の単語表記が統一されていないことが多いのと、自分用のリファレンスとして使うからです。
小さな変化はVerは変えずにしれっと内容を変更しますので、大きな変化がなければVerは変わりません。
一段目はVer.1です。 例:レ レー
二段目はVer.2です。 例: nu na
|
 |
レ レー
nu na
nu na
|
 |
カ カー
l la
l la
 |
|
 |
 |
キ ゲ キー ゲー
r ra re ro
r ra re ro
|
 |
ク クー
k ka
k ka
|
 |
メ メー
z za
z za
|
 |
 |
 |
ミ ピ ミー ピー
yu ya ye yo
yu ya ye yo
|
 |
ラ ラー
j ja
j ja
|
 |
サ サー
t ta
t ta
|
 |
セ セー
kh kha
kh kha
|
 |
シ シー
sh sha
sh sha
|
 |
 |
 |
テ ダ テー ダー
p pa pe po
p pa pe po
|
 |
 |
 |
ヤ ジャ ヤー ジャー
f fa fe fo
f fa fe fo
|
 |
 |
 |
ヨ ジョ ヨー ジョー
v va ve vo
v va ve vo
|
 |
 |
 |
ユ ジュー - -
g ga ge go
g ga ge go
|
|
|
プ マ ト
d ma b
d ma b
|
|
|
|
ニ オ タ ン
|
ム
mu
mu
発音概説
【Ver.1】
全体的にカタカナっぽく発音します。
日本語発音なので世界的には多分発音しづらいでしょうね。
全体的にカタカナっぽく発音します。
日本語発音なので世界的には多分発音しづらいでしょうね。
【Ver.2】
英語のアルファベットのように子音と母音を分かつことによりVer.1よりも発音が効率化しています。
子音が連続し発音が難しい場合は、その子音に母音"u"をつけて発音します。
アルファベットでマジューユを表記するときもこれに従います。
また同一の子音なら、可能であれば促音化しても良いです。
英語のアルファベットのように子音と母音を分かつことによりVer.1よりも発音が効率化しています。
子音が連続し発音が難しい場合は、その子音に母音"u"をつけて発音します。
アルファベットでマジューユを表記するときもこれに従います。
また同一の子音なら、可能であれば促音化しても良いです。
子音が連続する例
llsh→lulsh
llma→lulma
rbr→rubr
ptpe→putpe
llsh→lulsh
llma→lulma
rbr→rubr
ptpe→putpe
このとき"u"の発音は"ウ"っぽく発音します。
英語のように bus の u が [ʌ] になったりとかはしません。
英語のように bus の u が [ʌ] になったりとかはしません。
促音化する例
gararagga (gararagugaより発音が楽)
gararagga (gararagugaより発音が楽)
同じベースが連続する場合
同じベースが3つ直線に並ぶ場合、"ツ(ts) + 該当ベース音" と発音します。
直線でなければ ts は用いることはできません。
tutsvut , skutsgs , tsdutsgaなどが該当します。
直線でなければ ts は用いることはできません。
tutsvut , skutsgs , tsdutsgaなどが該当します。
イン
マジューユにおいては、ベースの中にベースが入ることがあります。
ベースの中にベースが入ることをインと呼びます。
また、インが起きている文字の外側のベースをアウトベース、内側のベースをインベースと呼びます。
ベースの中にベースが入ることをインと呼びます。
また、インが起きている文字の外側のベースをアウトベース、内側のベースをインベースと呼びます。
↓語例↓
 |
 |
 |
インが起きている文字を口頭で発音する場合は、
「ス(s)+(北にある)アウトベース音+インベース音+ス(s)」
と発音します。
したがって、→でインを起こした場合はスヤス。←でインを起こした場合はスジャスとなります。
「ス(s)+(北にある)アウトベース音+インベース音+ス(s)」
と発音します。
したがって、→でインを起こした場合はスヤス。←でインを起こした場合はスジャスとなります。
インは一つ内側までしか出来ません。つまり、三重丸などは出来ません。
また、インが起きているベースは区画計算の仕方が特殊です。
また、インが起きているベースは区画計算の仕方が特殊です。
インベースが「・」一つであった場合、縦横値は(2,2)と数えます。
それ以外の場合、縦横値はインベースのみで計算します。
それ以外の場合、縦横値はインベースのみで計算します。
ただし、ベース使用数についてはアウトベースも1つとカウントされます。
以下に、アウトベースとなりうるベースと、中身が空欄のときのイン時の字形を示します。
なお、中身が空欄のときは、「ス(s)+(アウトベース音)+ス(s)」と発音します。
またインが起きても形の変わらないものは一つのみの表示となっています。
なお、中身が空欄のときは、「ス(s)+(アウトベース音)+ス(s)」と発音します。
またインが起きても形の変わらないものは一つのみの表示となっています。
|
|
 |
|
 |
|
 |
|
|
|
 |
|
 |
レイヤー化
マジューユにおいては、ベースの上にベースが重なることがあります。
あるベースの下にベースがくることをレイヤー化と呼ぶことにします。
また、レイヤー化の起きるベースをレイヤーベース、レイヤーベースの下に来るベースをアンダーベースと呼ぶことにします。
(英語は苦手なので命名は適当です。間違ってても気にしないで下さい)
あるベースの下にベースがくることをレイヤー化と呼ぶことにします。
また、レイヤー化の起きるベースをレイヤーベース、レイヤーベースの下に来るベースをアンダーベースと呼ぶことにします。
(英語は苦手なので命名は適当です。間違ってても気にしないで下さい)
↓語例↓
 |
 |
 |
レイヤーが起きている文字を口頭で発音する場合は、
「ワ(wa)+(レイヤーベース音)+(アンダーベースの音)+ワ(wa)」
と発音します。
したがって、→でレイヤー化した場合はワヤワ。←でレイヤー化した場合はワジャワとなります。
(ver.1の発音ではワではなくレでしたが、✕と被るので変えました)
「ワ(wa)+(レイヤーベース音)+(アンダーベースの音)+ワ(wa)」
と発音します。
したがって、→でレイヤー化した場合はワヤワ。←でレイヤー化した場合はワジャワとなります。
(ver.1の発音ではワではなくレでしたが、✕と被るので変えました)
レイヤー化は一つのベースだけしか上に置けません。アンダーベースは収容区画いっぱいまで配置できます。
レイヤー化が起きているベースの区画計算の仕方は、
(レイヤーベースの縦横値)≦(アンダーベースの合計縦横値)
の場合、アンダーベースの合計縦横値がその単語の大きさとしてカウントされ、
(レイヤーベースの縦横値)≦(アンダーベースの合計縦横値)
の場合、アンダーベースの合計縦横値がその単語の大きさとしてカウントされ、
(レイヤーベースの縦横値)>(アンダーベースの合計縦横値)
の場合、レイヤーベースの縦横値がその単語の大きさとしてカウントされます。
の場合、レイヤーベースの縦横値がその単語の大きさとしてカウントされます。
ベース使用数についてはレイヤーベース1つとアンダーベースの数の合計がカウントされます。
ベース間の距離
マジューユにおいては、ベースとベースが隙間なくくっつくことがあります。
例えば、この人工言語の由来となる単語「マジューユ」は、各ベースがくっついています。
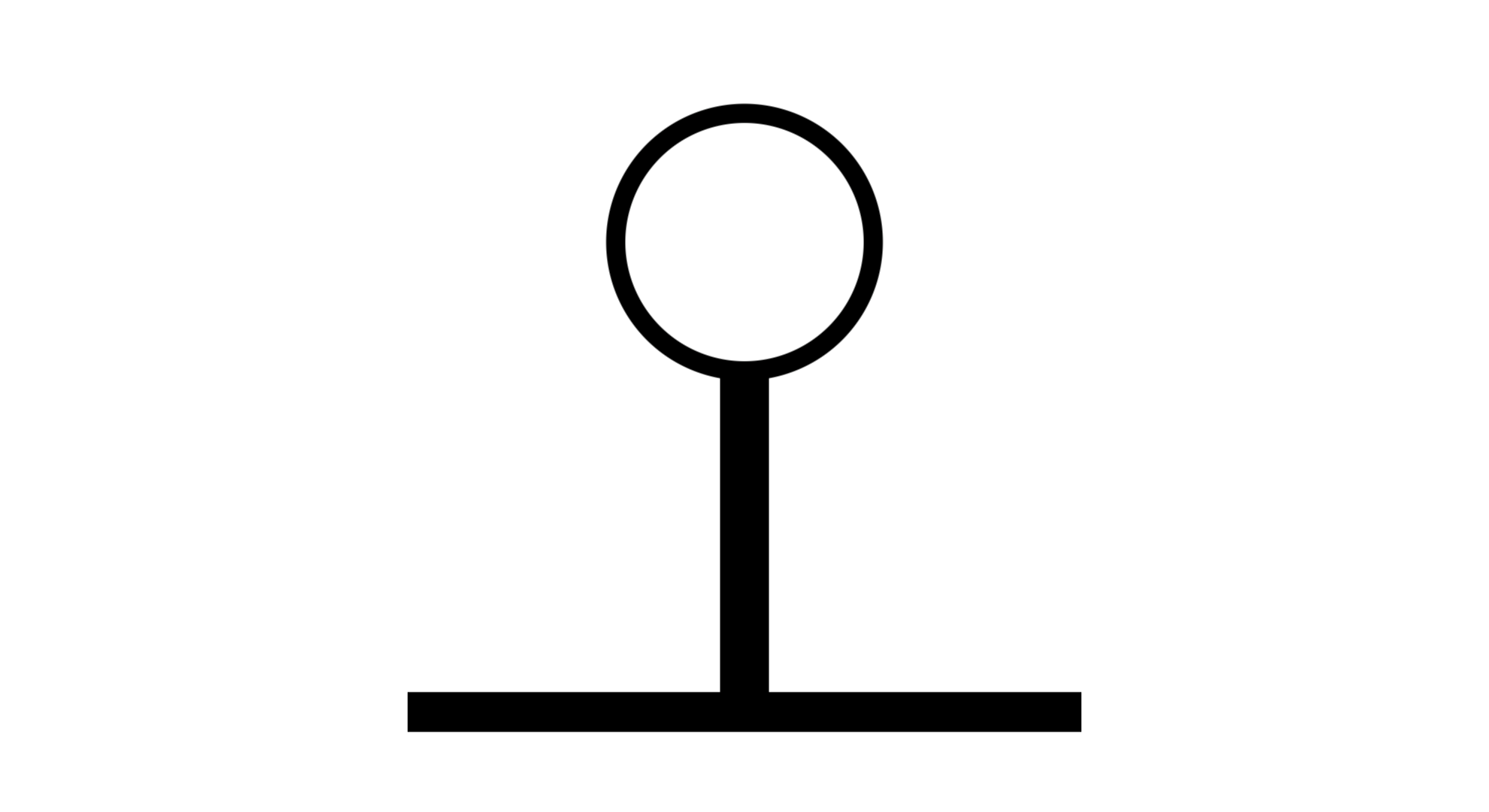
例えば、この人工言語の由来となる単語「マジューユ」は、各ベースがくっついています。

これについては口頭でどう区別するか未だ検討中です。
またIME制作においても何らかの影響を及ぼすことが予測されています。
またIME制作においても何らかの影響を及ぼすことが予測されています。
文法
まだ未定事項が多いので、大筋が決まったら書いていこうかな。……と思ってた時期があったのですが、あまりに決まらないので決まったことから小出しに書いていこうかなと思います。それ故、体系的な書き方はできませんのでご了承下さい。
・語順
今のところSOVで行こうかと思ってます。
私自身日本語話者なのでその方が作りやすいかなって……
今は英語がグローバルスタンダードなのでSVOにした方が国際補助言語的には良いのかなと思ったりもしたんですが、それを言い出したらベースとかいう独自規格作ってる時点で道を違えているので今更だと開き直りました。許してください。
私自身日本語話者なのでその方が作りやすいかなって……
今は英語がグローバルスタンダードなのでSVOにした方が国際補助言語的には良いのかなと思ったりもしたんですが、それを言い出したらベースとかいう独自規格作ってる時点で道を違えているので今更だと開き直りました。許してください。
・数量表現
1,000,000は英語ならOne million、日本語なら百万と言いますが、そういう表現についてです。
まず前提として、記数法は十進法を採用します。
マジューユにおける0~9の文字は見た目がなるべくアラビア数字に似るように造語します。が、数字はよく使うものなので、なるべく似せますが音素はできるだけ少なくなるようにします。優先度は音素の方が上だと考えているので、少しぐらい形がアラビア数字と比較して崩壊してても言いやすさを優先します。
日本語っぽく読むところもありますが、位取りの位置は英語と同じく3桁で取ります。
まず前提として、記数法は十進法を採用します。
マジューユにおける0~9の文字は見た目がなるべくアラビア数字に似るように造語します。が、数字はよく使うものなので、なるべく似せますが音素はできるだけ少なくなるようにします。優先度は音素の方が上だと考えているので、少しぐらい形がアラビア数字と比較して崩壊してても言いやすさを優先します。
日本語っぽく読むところもありますが、位取りの位置は英語と同じく3桁で取ります。
暫定のキリの良い数の読み方は以下になります。(今後変わる可能性大いにあり)
10:ジュー
100:パク
1,000:キノ
1,000,000:メナ
1,000,000,000:ギナ
10:ジュー
100:パク
1,000:キノ
1,000,000:メナ
1,000,000,000:ギナ
2桁の読み方は日本語的に読みます。
数字単体の読み方はまだ決まってないので(X)で表しますね。
10:ジュー
20:(2)ジュー
24:(2)ジュー(4)
83:(8)ジュー(3)
数字単体の読み方はまだ決まってないので(X)で表しますね。
10:ジュー
20:(2)ジュー
24:(2)ジュー(4)
83:(8)ジュー(3)
3桁の読み方は以下のようになります。これもほぼ日本語ですね。
100:パク
105:パク(5)
521:(5)パク(2)ジュー(1)
729:(7)パク(2)ジュー(9)
100:パク
105:パク(5)
521:(5)パク(2)ジュー(1)
729:(7)パク(2)ジュー(9)
4桁も同じ感じです。
1,000:キノ
1,010:キノジュー
2,118:(2)キノパクジュー(8)
5,061:(5)キノ(6)ジュー(1)
1,000:キノ
1,010:キノジュー
2,118:(2)キノパクジュー(8)
5,061:(5)キノ(6)ジュー(1)
5桁からは日本語と違い万ではありません。
10,000:ジューキノ
41,068:(4)ジュー(1)キノ(6)ジュー(8)
70,642:(7)ジューキノ(6)パク(4)ジュー(2)
日本語で言うと、41,068を四十一千六十八って読んでる感じでしょうか。
10,000:ジューキノ
41,068:(4)ジュー(1)キノ(6)ジュー(8)
70,642:(7)ジューキノ(6)パク(4)ジュー(2)
日本語で言うと、41,068を四十一千六十八って読んでる感じでしょうか。
大体わかったと思うので6桁を飛ばして7桁の例示をして整数については終わろうと思います。
7桁
1,000,000:メナ
1,350,764:メナ(3)パク(5)ジューキノ(7)パク(6)ジュー(4)
1,000,000:メナ
1,350,764:メナ(3)パク(5)ジューキノ(7)パク(6)ジュー(4)
- 小数の読み方
整数部分を上記の読み方に従って読んでから、「ムプ」(点の意)を挟んで小数点以下の数字をそのまま読む感じです。
これもほぼ日本語と同じですね。
これもほぼ日本語と同じですね。
121.756:パク(2)ジュー(1)ムプ(7)(5)(6)
分数の読み方や演算関係の読み方は未定です。あとで書き足します。
・今のところ採用しない予定のもの
「~しない」って言うのはあんまり言っても意味がない気がしますが、文法が決まらないので仕方ありません。(少しでも進んでる感があったほうが私のモチベが上がるので許してください)
- 活用と曲用
活用は今後復活する可能性がありますが、曲用は多分ないです。
ロシア語で格変化とかをやってると曲用君はちょっと嫌厭しちゃいますね……。
活用に関しては、動詞の過去形などを表すときに日本語的な用い方をしようかなとも思ってたのですが、中国語の副詞を使って時制を表現するのがとても合理的だと思ったのでそれを採用しようかなと考えています。
ロシア語で格変化とかをやってると曲用君はちょっと嫌厭しちゃいますね……。
活用に関しては、動詞の過去形などを表すときに日本語的な用い方をしようかなとも思ってたのですが、中国語の副詞を使って時制を表現するのがとても合理的だと思ったのでそれを採用しようかなと考えています。
- スペーシング
スペーシングはなくて良いかなと思っています。
マジューユでは「動詞、形容詞、名詞、それ以外の品詞」が品詞区別ベースによって明示されるのでスペーシングがなくても十分品詞の見分けはつくだろうと判断します。
マジューユでは「動詞、形容詞、名詞、それ以外の品詞」が品詞区別ベースによって明示されるのでスペーシングがなくても十分品詞の見分けはつくだろうと判断します。
アルファベットは全てが表音文字で成り立っているため、単語間の視覚的区別がしにくいです。これをスペーシングによって解決しています。
主観的な感想ですが、日本語では、平仮名は多くは文法的な役割を果たしているように感じます。例えば助詞「は/が/の」などは平仮名です。漢字で文法的作用を起こすものは少ないでしょう。そして、漢字と平仮名では視覚的に両者の乖離が大きいですから、視覚的な区別は容易でありましょう。なのでスペーシングが必要ありません。
中国語においては……ちょっとよくわからない(無能)
主観的な感想ですが、日本語では、平仮名は多くは文法的な役割を果たしているように感じます。例えば助詞「は/が/の」などは平仮名です。漢字で文法的作用を起こすものは少ないでしょう。そして、漢字と平仮名では視覚的に両者の乖離が大きいですから、視覚的な区別は容易でありましょう。なのでスペーシングが必要ありません。
中国語においては……ちょっとよくわからない(無能)
マジューユでは、日本語ほど文法用の文字とそれ以外の文字の区別がはっきりしません。これは、文法にかかるものも、名詞などそれ以外のものも、同じ要素(ベース)から成り立っているからです。なので、特定の記号を語の直前直後に置くことによって区別しようかなと思います。
- 複数形
単語の単数・複数の区別はつけない予定です。日本語と同じですね。
いちいち数を気にするのはちょっと学習効率が良くなさそうなのと、私が日本語話者なので単語の単数複数の区別に馴染みがありません。
いちいち数を気にするのはちょっと学習効率が良くなさそうなのと、私が日本語話者なので単語の単数複数の区別に馴染みがありません。
- 尊敬語
日本語のような尊敬語・謙譲語の区別は煩雑になるのでつけません。
- 序数詞
「本が一冊ある」の「冊」、「うさぎが二匹いる」の「匹」みたいなのは学習効率を鑑みて不採用とします。なので、言い方的には「本が1ある」「うさぎが2いる」みたいな感じになるかな。
- 名詞の性
これも学習効率を鑑みて採用しません。ロシア語をやってるとこの苦痛がわかる。
検討
- 動詞・形容詞・名詞以外の品詞であることを明示するベースの案
現状、表音ベースと称して文法用のベースは文法用途でしか使えないことになっているのですが、これだと外来語をうまく表せなくなる可能性が高そうです。
特に固有名詞などはいろいろな音素で成り立っている故、表音ベースの音も借りなければ表せない音が相当あることは明白でしょう。
特に固有名詞などはいろいろな音素で成り立っている故、表音ベースの音も借りなければ表せない音が相当あることは明白でしょう。
ところで日本語では平仮名は助詞や接続詞など文法的な役割をもつ語に多く使われていますが、使われる音は漢字と同じ要素から成っています。五十音のなかで文法用の文字として用いられているのは「を」だけですし、「を」も「お」と音が被っています。つまり、音自体は名詞や動詞と被っていても文脈で十分判断できるということではないでしょうか。
以上を踏まえ、マジューユも特定の音が文法用にしか使えないというのは窮屈なので、日本語方式的に他のものにも流用できたほうが良かろうと思います。実際、文法に作用するベースが少量だと音素が相互干渉を起こして学習効率が悪くなる可能性があります。
そこで、文法に作用するものであるということを明示するというベースを作るのはどうでしょう。その記号一つだけを語頭に置けば、その単語は文法的に作用するものであり、動詞や名詞、形容詞ではないことが明示できるので、普通の表語ベースと文法に作用する表語ベースが(同じ字形にも関わらず)差別化できるということになります。これで音素の相互干渉は防げそうです。
懸念として、文法に関わる単語全部にその記号がつく分少し冗長になるかもしれませんが、大体文法に関わる単語とかは短い音素であることが多いので、そんなに冗長にはならないんじゃないかという期待があります。
懸念として、文法に関わる単語全部にその記号がつく分少し冗長になるかもしれませんが、大体文法に関わる単語とかは短い音素であることが多いので、そんなに冗長にはならないんじゃないかという期待があります。
「動詞・形容詞はすでに明示化されているので、それ以外はだいたい文法に関わるベースであることは想像つくのでは?」とも思ったのですが、名詞は明示化されていないので、それを区別できるようになるのは結構良さげです。
まとめると、マジューユの品詞区別ベース体系は、動詞・形容詞・名詞・その他の文法関係詞ということになりそうです。
国際補助言語としての展望
「空港の案内板とかでたまに目にする…」みたいなポジションの言語を狙っていきたい。
あと、ネット上にマジューユで書き込まれてるコメントがあるとか、そこらへん。
あと、ネット上にマジューユで書き込まれてるコメントがあるとか、そこらへん。
IME
マジューユは将来的に(かなり遠い未来かもしれないですが)IMEで直接入力ができるようにしたいです。
ここでいう直接入力とは、ハングルのIMEのような感じで、要素を自動で組み合わせてくれるみたいなものを指します。
また直接入力以外に、他の既存言語からの変換にも対応できるようにできたら良いなと最近思い始めました。
例えば英語で「person」と入力すれば「i」が変換候補に、「people」と入力すれば「iii」が変換候補に表示される、みたいな。
ここでいう直接入力とは、ハングルのIMEのような感じで、要素を自動で組み合わせてくれるみたいなものを指します。
また直接入力以外に、他の既存言語からの変換にも対応できるようにできたら良いなと最近思い始めました。
例えば英語で「person」と入力すれば「i」が変換候補に、「people」と入力すれば「iii」が変換候補に表示される、みたいな。
なお製作者はプログラミングには詳しくありませんので、
IMEを開発するとなると、自分で勉強するか人に頼むかになりますが、いずれにせよどういう仕組みで入力するのかを考えておく必要があります。
とりあえず現時点でのガバガバ案を以下に示します。
IMEを開発するとなると、自分で勉強するか人に頼むかになりますが、いずれにせよどういう仕組みで入力するのかを考えておく必要があります。
とりあえず現時点でのガバガバ案を以下に示します。
草案
キーボードから入力を受け取る
↓
入力文字数(最大7文字)に応じて配置パターンを呼び出す
↓
呼び出した配置パターンにベースの縦横の長さの値を代入する
↓
代入された値を元に、縦横の長さの和を行列ごとに求め、その最大値を出す
↓
(横の最大値)>7 or (縦の最大値)>6
となる場合のパターンを除外する
↓
残った配置パターンに対して、座標点「・」が各ベースの中心になるよう画像出力する(要検討)
キーボードから入力を受け取る
↓
入力文字数(最大7文字)に応じて配置パターンを呼び出す
↓
呼び出した配置パターンにベースの縦横の長さの値を代入する
↓
代入された値を元に、縦横の長さの和を行列ごとに求め、その最大値を出す
↓
(横の最大値)>7 or (縦の最大値)>6
となる場合のパターンを除外する
↓
残った配置パターンに対して、座標点「・」が各ベースの中心になるよう画像出力する(要検討)
変換候補が複数ある場合は、機械学習などによって頻度の高い単語を優先して表示させる。
配置パターン(6,7はまだ作成途中です)
動詞アニメーション機能案
マジューユの動詞はわりかし直観的でわかりやすいと思う(自画自賛)。
それがアニメーションという形で動詞が本当に動く文字になったら、
もっとわかりやすくなると思いませんか?
それがアニメーションという形で動詞が本当に動く文字になったら、
もっとわかりやすくなると思いませんか?
マジューユはネット上で広めていくということを加味すれば、
「文字が動く言語」を作ることも技術的には不可能ではないはず。
ガラケーの時代でも動く絵文字を送ることが出来たのだから、マジューユに出来ない道理は無いと思うのです。
「文字が動く言語」を作ることも技術的には不可能ではないはず。
ガラケーの時代でも動く絵文字を送ることが出来たのだから、マジューユに出来ない道理は無いと思うのです。
というわけで、動詞をアニメーション化した時にどういう動きになるのかをシミュレーションしたのが以下の動画群になります。
あれめっちゃいい感じじゃね?
電光掲示板にマジューユが使われている未来が見えるぞ……(自信過剰
(右クリックなどしてループ再生で見るのがオヌヌメです)
電光掲示板にマジューユが使われている未来が見えるぞ……(自信過剰
(右クリックなどしてループ再生で見るのがオヌヌメです)
 |
 |
 |
 |
 |
 |
 |
 |
手話表現案
殆どのベースは片手で表せるくらい単純な形をしているので、手話にも対応できそうな気がします。
手話に関する知識がゼロなので大分憶測で物を言っていますが、とりあえず思いついたのでメモしておきます。
以下はそれっぽい手の動きの案です。
手話に関する知識がゼロなので大分憶測で物を言っていますが、とりあえず思いついたのでメモしておきます。
以下はそれっぽい手の動きの案です。
loading tweet...— N.こづけ (@cat_in_ricebran) July 15, 2022
追記です。手話には腕以外にも言語を表す変数として顔があり、その顔も眉や口、視線など細かくパラメータが分かれていて、それらを用いてもっと効率化が図れることがわかりました。
マジューユを手話に翻訳するなら今後はそこらへんも視野に入れて改善していきたいですね。
マジューユを手話に翻訳するなら今後はそこらへんも視野に入れて改善していきたいですね。
