Midiセントで5000~8000の音域で15音の音列を作る。以下の規則を課す。
- 同一の音がない(オクターブを含め)
- 四分音まで使う
公式マニュアルのパッチの問題点
- テスト用パッチ test-octave-quartertone の設計ミス。例えば6001(ほぼC4)と6050(Cの四分音上)を与えた場合には、これらは違う音だと判定し、nilを出力しなければならないが、実際はtが出る。
- 1刻みの乱数を発生させて後で四捨五入的に四分音を作る方式は計算に無駄が多く、さらに5000と8000(範囲の端の音)の出る確率はそれ以外の音の出る確率の半分になる(5050は5025~5074の範囲からできるのに対し、5000は5000~5024と半分の範囲しかないため)。
- 1回1回新規でremove-dupするので、既にダブりが判明している要素にも何度も同じ計算が発生する。オクターブの削除も1刻み→四分音(50cent刻み)の変換も毎度毎度起こっている。
改善
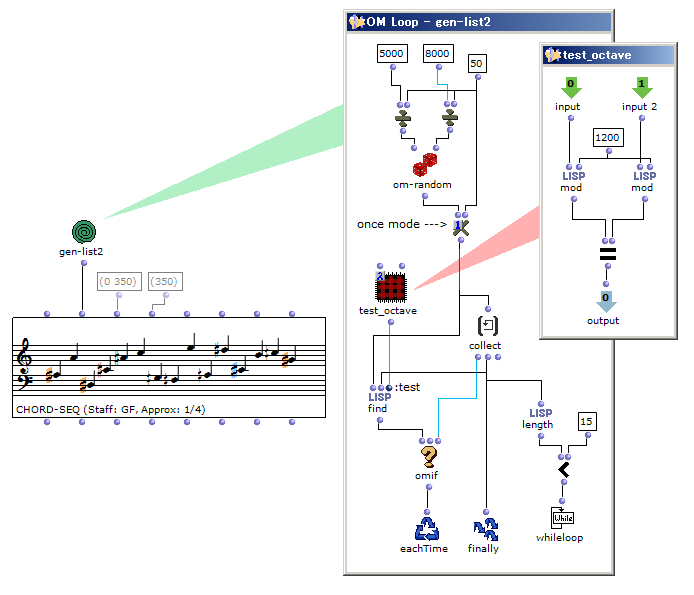
- 乱数を事前に50cents刻みにして、1刻み→四分音(50cent刻み)の変換をいちいち行わない。
- テスト用パッチが正しく判定を返すように修正。modは割り算の余りを返す関数。別にom//でもおk。
- 乱数を取ってきて、いままでcollectした中に同じ音が1つもなかったらその音をcollectする、というようなロジック。
- findによるオクターブの削除計算もムダがあるが、工夫すれば少なくできる(例えば、car部にオクターブ削除後の値をメモっておいて使うとか→画像)。
さらに
公式のものも改善版も、集めたい要素数が集められる限界に近付くにつれ効率が悪くなる。それは次のような理由である。
例えば、C4、C#4、・・・、B4 の12音から、12コを使うランダムな音列を作るとする。
そしてomloopのループをしていく中で、C4~Bb4までの11音をcollectし終えたとする。
取ってこなければいけない最後の1音は、言うまでもなくB4である。しかし乱数はそんなことお構いなしであって、B4を出す確率は1/12であり、つまり1音集めるためだけに平均で12回(運が悪ければもっと)ループが発生する。
例えば、C4、C#4、・・・、B4 の12音から、12コを使うランダムな音列を作るとする。
そしてomloopのループをしていく中で、C4~Bb4までの11音をcollectし終えたとする。
取ってこなければいけない最後の1音は、言うまでもなくB4である。しかし乱数はそんなことお構いなしであって、B4を出す確率は1/12であり、つまり1音集めるためだけに平均で12回(運が悪ければもっと)ループが発生する。
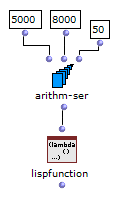
これを改善するには、om-randomを使うのではなく、使う音のリストを用意しておいてnth-randomで選び、選んだ数は元の集合から消すといったようなロジックが考えられる。
しかし、omloopでこれをするにはstoreオブジェクトとかslotとか、かなり込み入ったことをしなければならない。
しかも作ったところで、母集合が大きい場合や集めたい要素数が少ない場合は、前述した無駄ループのデメリットがあってなおそっちの方が性能がいい。
とりあえずlispfunctionで書いた例を載せておくが、筆者のプログラミングは怪しいのでもっといいやり方があるかもしれぬ。
しかし、omloopでこれをするにはstoreオブジェクトとかslotとか、かなり込み入ったことをしなければならない。
しかも作ったところで、母集合が大きい場合や集めたい要素数が少ない場合は、前述した無駄ループのデメリットがあってなおそっちの方が性能がいい。
とりあえずlispfunctionで書いた例を載せておくが、筆者のプログラミングは怪しいのでもっといいやり方があるかもしれぬ。

(lambda (lst)
(let ((a) (res))
(setq lst ([[mapcar]] #'(lambda (x) ([[cons]] (mod x 1200) x)) lst))
(loop
(if (>= ([[length]] res) 15) (return res))
(setq a (nth-random lst))
(setq lst (delete (car a) lst :key 'car :test '=))
(push (cdr a) res)))))
