現状の生成AIが抱える問題点を総合的・包括的にまとめています。
| + | 編集者の方へ |

【目次】
- 【0. はじめに】
- 【1. 生成AI開発時のデータ収集に関する問題】
- 【2. 偽情報・コンテンツの作成・拡散】
- 【3. AI製ポルノ・AI製児童ポルノ】
- 【4. デジタルデータの信頼性が低下する可能性】
- 【5. インターネットの汚染】
- 【6. ハルシネーション(幻覚)問題】
- 【7. クリエイティブ関係における生成AIの問題点】
- 【8. 学術・研究に関する問題】
- 【9. 教育に関する問題】
- 【10. 失業・働き方に関する問題】
- 【11. 電力・環境に関する問題】
- 【12. 脱獄・犯罪利用】
- 【13. その他の問題点】
- 【14. 生成AIに関する論点】
- 【関連ページ】
【0. はじめに】
いま世間は生成系AIの話題で持ちきりとなっています。この技術が私たちを変えてくれるのだ、人類の労働を効率化し果ては労働から解放される、より大きな繁栄へ導くのだとの言説が盛んに叫ばれています。しかしながらその陰で、まさに今現在生成AIによって精神的に追い込まれている人々もいます。
このページでは生成AIが現在引き起こしている・将来引き起こしうる問題について解説しています。
クリエイティブ関連について触れているのは、画像・テキスト・音楽・音声生成AI等においてクリエイター達が創り上げた作品たちが無断で利用されているという背景があるためです。つまりクリエイター達が創った作品を生成系AIを開発する企業や一部生成系AIユーザーが許可や対価なしに生成系AIに取り込んで利用し、人間では到底成し得ないようなスピードで量産する事でコンテンツの価値を下げ、果てはクリエイターを経済的・精神的苦境に追い込む構造が世界的に批判されているためです。
さらに、生成系AIは私たちが生きる社会の中でも大きな問題を起こしている・将来起こし得るとの批判があります。代表的なものは「偽情報の作成が簡単になった」という部分です。例えば画像生成AIでは、政治家が逮捕されている様子を表現した精巧な偽画像が作成されたり、災害時にデマを流す用途として使用されるケースが発生しています。音声生成AIでは特定人物の声を抽出した上で精巧なボイスチェンジャーとして用いられ、身内に対する詐欺用途として悪用されるといった問題が発生しています。
このような問題は昔からあったものですが、生成系AIの普及に伴ってかなり簡単に偽の情報を作成したり他人を騙す事が出来るようになったという事が決定的な違いです。偽情報によって社会を混乱させたり個人を中傷することがより簡単になってしまいました。
人類の歴史上、画期的な技術が生まれた事による文明の進歩や生活の向上は何度もありましたが、同じぐらい新技術によるリスクにも曝されてきました。技術に囲まれて暮らす私達だからこそ、技術がもたらす良い面と悪い面どちらも考えて議論していくことが大切だと考えています。
0-1. AIとは、生成AIとは
AI(Artificial Intelligence、人工知能)とは、一般的には「人の脳の働きをコンピューターなどで人工的に作り出した技術(*1)」を指す。「AI」と名乗る技術は、自動運転、画像認識、明日の天気の予想、ゲームの敵キャラクターの動きなど様々な場面で使われており、社会においてすでに広く普及している。一方で「AI」という名で社会に実装、あるいは宣伝されている技術や製品の範囲はあまりにも広いため、何が本当のAI技術であってそうでないのか、曖昧であり、明確な線引きは難しいともされる。
また、AI技術は画像認識や音声認識、自然言語処理、機械の制御など用途ごとに様々な種類のものがあるが、その中でも文章や画像、音楽などのコンテンツを出力するAI技術や製品を「生成AI(Generative AI)」と言う。
生成AIと密接に関与する技術として「コンピューターに大量のデータを読み込ませてその中にある規則性や法則性等を見つけ出す手法・技術(*2)」である、「機械学習(Machine Learning)」がある。
機械学習はAI分野の中の一分野であり、さらにはその機械学習分野をより発展させた分野として「深層学習(Deep Learning)」が存在し、現状の生成AIでは主に「機械学習」と「深層学習」の技術・手法が使われている。
機械学習はAI分野の中の一分野であり、さらにはその機械学習分野をより発展させた分野として「深層学習(Deep Learning)」が存在し、現状の生成AIでは主に「機械学習」と「深層学習」の技術・手法が使われている。
▼生成AIの開発からコンテンツの生成に至るまでの大まかな流れ。
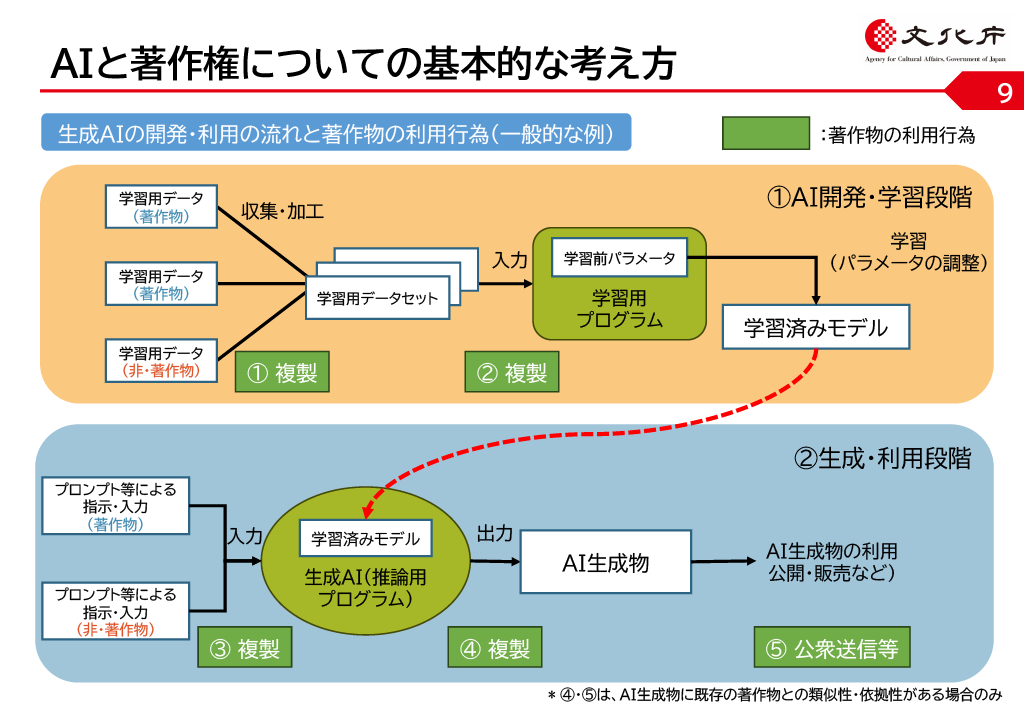
引用:文化庁[PDF]令和6年度著作権セミナー「AIと著作権Ⅱ」・第1部 生成AIと著作権・P9より
※ただし本図は、生成AIの技術的な仕組みというよりも、法律上の取り扱いについて解説するのが主である点に注意。

引用:文化庁[PDF]令和6年度著作権セミナー「AIと著作権Ⅱ」・第1部 生成AIと著作権・P9より
※ただし本図は、生成AIの技術的な仕組みというよりも、法律上の取り扱いについて解説するのが主である点に注意。
生成AIを出力するコンテンツ毎に分類すると、文章生成AI、画像生成AI、音楽生成AI、動画生成AI、音声生成(合成)AIなどがある。
生成AIの具体的な活用法として、文章要約、文章生成、翻訳、それに伴う企業の業務の効率化、画像・音楽・映像作品などの制作、またはその効率化などがあり、これらにおいて効果を発揮すると期待されている。
本ページは、この生成AI技術・製品のみに存在する特性、あるいは開発のあり方を原因として引き起こされる問題をまとめることを目的としている。そのため、生成AIに該当しないと考えられる他のAI技術については必要が認められた時以外に触れることはない。
▼LLM/大規模言語モデル(テキスト系生成AI)の仕組み。
▼画像生成AIの仕組み。
0-2. 生成AIの主な問題点
生成AIの問題点といえば何があるだろうか。
特定人物の写真にAIを用いて性的な加工を行う「ディープフェイクポルノ」、AIフェイクが溢れることで写真や映像などの信ぴょう性が大きく損なわれる事、クリエイター関連の問題など様々なものがある。
特定人物の写真にAIを用いて性的な加工を行う「ディープフェイクポルノ」、AIフェイクが溢れることで写真や映像などの信ぴょう性が大きく損なわれる事、クリエイター関連の問題など様々なものがある。
つまり、問題の範囲が非常に広く、さらにはそれぞれの問題が関係しあう事も多いため問題点を簡潔に説明する事が難しい。しかし少々強引だが、それぞれの問題をいくつかの傾向に分けることが出来る。
生成AIの問題点はおおむね以下の3つの傾向に分類可能である。
- ①:無断利用である事による問題。(主に開発時の問題)
- ②:誰でも簡単にある程度のクオリティを持つコンテンツが作れ、なおかつ大量生産できる事による問題。(主に利用時の問題)
- ③:その他の問題。
まずは①の「無断利用であることによる問題」から見てみよう。この問題は主に生成AIの開発段階で発生する。
生成AIは大量のデータを収集し、集めたデータの中にある規則性を発見する過程が必要だ。
また、生成AIが生成できるコンテンツの品質やその範囲は、良くも悪くも収集したデータの量や質、データの内容の多種多様さに左右される。
また、生成AIが生成できるコンテンツの品質やその範囲は、良くも悪くも収集したデータの量や質、データの内容の多種多様さに左右される。
このデータ収集段階において、どこからコンテンツが集められるのか。それは主にインターネットである。ネットから画像、テキスト、音楽、声、映像といったあらゆるデータが集められている。(あまりにも多くのデータが集められているため、近く2026年にはデータが枯渇するとの懸念もある。(*3)(*4))
これらのデータ収集は一部の例外を除き、基本的にコンテンツ制作者や権利所有者の許諾を取らずに行われている。
この無許諾でのデータ収集で起こる問題は、さらに「不適切なコンテンツの収集・素材化に伴う不適切なAIコンテンツの拡散」や、「作品や記事などのコンテンツを一方的に無許諾で使われた上に、競合コンテンツを大量生成されるという形でクリエイターをはじめとするコンテンツ制作者が不利益を被る構造」の二つに分けることが出来る。
例えば、画像生成AI開発のために集めたデータにポルノコンテンツが入っていれば、それに基づいてAIポルノが生成できる。反対にいえば、ポルノが無ければ生成できない。
イラストや音楽、小説など創造的なコンテンツを生成可能な生成AIでも、プロアマや実力を問わず様々なクリエイターが制作した作品データが大量に集められた上で構築されていることが多い。
出来事や知識を教えてくれるAIでも、その「元ネタ」は報道機関の記事やブログ、Wikiなどである。
イラストや音楽、小説など創造的なコンテンツを生成可能な生成AIでも、プロアマや実力を問わず様々なクリエイターが制作した作品データが大量に集められた上で構築されていることが多い。
出来事や知識を教えてくれるAIでも、その「元ネタ」は報道機関の記事やブログ、Wikiなどである。
また、開発時のデータ収集過程における問題は、「集めたデータの内容や量に出力できるコンテンツの種類や質も左右される」という生成AIの特性上、コンテンツの生成過程(利用段階)で起こる問題とも強く関係している。
次に、②の「誰でも簡単にある程度のクオリティを持つコンテンツが作れ、なおかつ大量生産できる事による問題」を見てみよう。この問題は主に生成AIの利用段階で発生する。
生成AIが引き起こす問題の一つとして、「ディープフェイク」がある。ディープフェイクとは、AI技術の一つであるディープラーニングを用いて作られる偽物の画像や動画、音声などを指す。ディープフェイク技術を用いて作られたコンテンツは、すでに本物か偽物か見分けが付かなくなりつつある。
以前から同様の技術は存在していたものの、生成AIが本格的に登場して誰でも簡単に使えるようになった事で、ディープフェイクに関する事件や問題も急増している。
ディープフェイクの代表例として、特定の人物の不評や誤解に繋がるようなデマ、災害や戦争でのデマ、偽ポルノの作成などがある。
ディープフェイクの代表例として、特定の人物の不評や誤解に繋がるようなデマ、災害や戦争でのデマ、偽ポルノの作成などがある。
ディープフェイク技術は特定の人物の顔立ちや声に似せたフェイクの作成が可能であり、作成の対象には、政治家や俳優といった有名人から一般人まで立場を問わず誰でもなり得る。
これによって、知らない所で勝手に自分の信頼を傷つけるようなフェイクや、あるいは社会を大規模に混乱させるようなフェイクが広まる事態がすでに起きている。
これによって、知らない所で勝手に自分の信頼を傷つけるようなフェイクや、あるいは社会を大規模に混乱させるようなフェイクが広まる事態がすでに起きている。
また、「フェイク」といえど、現行生成AIが出力できるコンテンツの範囲は広いため、様々な利用(悪用)のされ方をしている。AIで作られた偽の実験結果による科学的成果の偽装、就職活動におけるAI製の偽プロフィール、家族など親しい人の声や容姿を模したAIで行われる詐欺、政策に関する意見を国や自治体が募集するパブリックコメント制度での偽コメントの氾濫、写真や声を用いる認証システムの無効化、ネット上に低品質な偽情報が大量に拡散することによって情報を得る場所としてのインターネットが破壊されること、有名クリエイターのスタイルを再現したAIコンテンツを用いたなりすましや政治利用、AIフェイクが溢れることによるデジタルデータそのものの信頼性低下、それに伴う裁判など重要な場における混乱の可能性など、問題点の枚挙に暇がない。
このような問題点を指摘する意見に対し「以前も出来た」とする反論がある。確かに一部の問題はそうだ。しかしながら、「スキルを持った個人がある程度時間をかけなければ出来ない」のと、「誰でも簡単に出来る」のは及ぼす影響が全く異なると言っても良い。
AIフェイクを見分けられるようにすれば問題が解決すると思えるが、これも難しい。世界的に法制度の整備や判別ツールの開発も進んでいるが、これらは確実な対策とは言えない。すでに人間の目や耳などの五感でも見分けられなくなりつつある。
この他にも、人間が意図を持って作るAIフェイクではなく、生成AIの技術的仕様などを原因としてAIが嘘情報を回答してしまう「ハルシネーション」や、AI企業のセーフティーを突破して爆弾の作り方や不正なプログラムなど不適切な情報を出力させる行為「脱獄」も問題視されている。
次の項目より、それぞれの問題点を詳細に解説する。
▼生成AIの主な問題点。
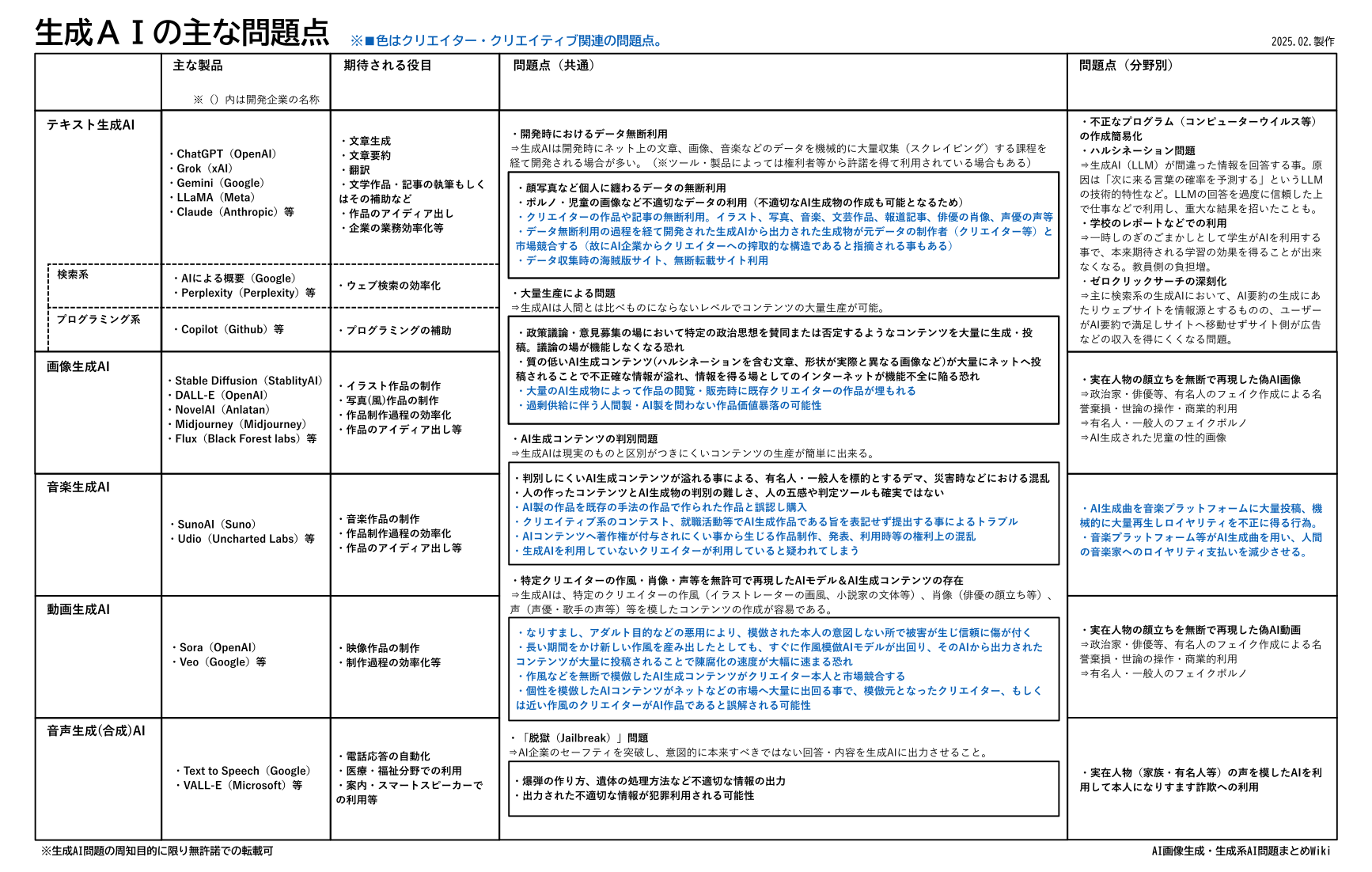

| + | ※2025年4月7日以前の記載 |
【1. 生成AI開発時のデータ収集に関する問題】
生成AIを開発する際には、テキスト、画像といったデータが大量に必要となる。
大量のデータを集める際に利用される方法として、インターネット上のウェブサイトをウェブクローラーで巡回し、データや情報を取得(複製)する方式(スクレイピング)を用いられる事が多い。そして、収集したデータを元に機械学習のための処理を行った「データセット(Dataset)」を作成し生成AI開発に利用する。また、(機械学習への利用や権利者の意思とは関係なく)あらかじめ収集され、ウェブサイト上に公開されたデータ群をデータセットとして利用することもある。
大量のデータを集める際に利用される方法として、インターネット上のウェブサイトをウェブクローラーで巡回し、データや情報を取得(複製)する方式(スクレイピング)を用いられる事が多い。そして、収集したデータを元に機械学習のための処理を行った「データセット(Dataset)」を作成し生成AI開発に利用する。また、(機械学習への利用や権利者の意思とは関係なく)あらかじめ収集され、ウェブサイト上に公開されたデータ群をデータセットとして利用することもある。
収集されるのは、報道機関の記事やブログといった「情報」、論文といった「学術・研究」、イラスト、写真家の撮影した写真、音楽、小説、声優の声、3Dモデル、映像作品・動画といった「創作物」、メールアドレスや個人の顔写真といった「個人データ」など非常に広範囲である。
大げさかもしれないが「デジタルデータ化できるあらゆるコンテンツ」が収集されている、あるいは収集されうると考えるぐらいがちょうどいいのかもしれない。
大げさかもしれないが「デジタルデータ化できるあらゆるコンテンツ」が収集されている、あるいは収集されうると考えるぐらいがちょうどいいのかもしれない。
このデータ無断利用の問題は主に、「①顔写真、医療記録など個人に関するデータの無断利用」、「②ポルノコンテンツなど不適切データの利用」、「③クリエイター・権利者が権利を有するデータの無断利用」に分けられる。
また、このデータの無断収集・利用行為は、俗に「無断学習」という名称で呼ばれることもある。
この問題を一番最初に解説しているのは、生成AIが持つ「出力できるAIコンテンツの範囲や質は、開発時に利用したデータの量や質、多種多様さに依存する」という特性が、生成AIの他の問題と強く繋がっているからである。ディープフェイクポルノが作成可能なのはポルノコンテンツを利用したからであり、有名キャラクターのAI画像や動画などを作成可能なのはそのキャラクターに関するコンテンツを利用したからである。
1-1.データ収集過程における諸問題
①個人に関するデータの無断利用
データ収集過程において、個人がアップロードした写真などといった個人データが生成AI開発に利用されている。
これらのデータはインターネットから無差別に収集する事が一般的だが、一方でSNSにおいてSNS運営とAI開発を同時に行っている企業が自社SNSに投稿された自撮りなどの写真や文章といったデータを利用しているケースもある。(X/旧Twitter(*5)やInstagram、Facebook(*6)など。当Wiki「強制オプトイン」の項目も参照)
これらのデータはインターネットから無差別に収集する事が一般的だが、一方でSNSにおいてSNS運営とAI開発を同時に行っている企業が自社SNSに投稿された自撮りなどの写真や文章といったデータを利用しているケースもある。(X/旧Twitter(*5)やInstagram、Facebook(*6)など。当Wiki「強制オプトイン」の項目も参照)
SNSに自身の顔などをはじめとする写真や文章といった個人にまつわる情報を投稿している人は当然、生成AIの開発に使われることをあらかじめ想定し承認していた訳ではなく、中には無断で素材にされることへの不快感を持つ人もいるだろう。
ChatGPT(米AI企業OpenAIが開発)をはじめとする、テキスト系の生成AIにおいて学習データとして利用した個人情報を抜き出せたとの報告が上がっている。2023年12月には、ChatGPTのセキュリティを破り、学習データとして使われた氏名、電話番号、住所などの個人情報を抽出する事に成功したと研究者が発表。(*7)また、ChatGPTに少し手を加える事で通常の操作では手に入れることが出来ない個人のメールアドレス(※公開されているもの)を取得できたとの報告もある。(*8)
画像生成AIにおいても、データセット内に個人の医療記録が見つかったとする指摘がある。(*9)
この個人データを生成AI開発に無断で利用している事(またはその疑惑に対し)、各国機関による指導や個人による訴訟も起きている。
2023年3月、イタリアの個人データ保護当局(GPDP)が、OpenAIに対し学習データにオンラインで共有されている個人情報が含まれていると指摘、EUの個人情報の取扱いに関する規制「一般データ保護規則(GDPR)」に違反したとして同国内でのサービス提供を一時中止するよう命じた。(*10)これを受けOpenAIは個人情報削除プラットフォームを設けるなどの対策を実施し4月末にサービス提供を再開。しかし、GDPR違反の疑惑に基づく捜査は継続しており、2024年1月にイタリアはGDPR違反を通知した。(*11)また、イタリアは2025年1月に中国のAIモデルDeepseekに対しても、個人データ収集の目的やAI学習データの内容が不透明な事などを理由としてデータ処理を制限し調査を開始すると明らかにした。(*12)
ヨーロッパ諸国は、SNSを運営する企業であるMetaやX(旧Twitter)に対しても指導を行っている。先述したように、生成AI開発を行っている企業の中には同時にSNSの運営も行っている場合もあり、SNSに投稿されたコンテンツを生成AIの学習データとして用いるとの規約改定を行う企業も存在する。これが問題視されることとなった。
Metaは2024年5月にプライバシーポリシーを更新し、Metaが運営するSNS(フェイスブック、インスタグラム、スレッズ等)に投稿されたデータをAIの学習データに利用すると発表。この発表に対し、アイルランドやイギリスのデータ保護機関などがユーザーのコンテンツを利用する事について一時停止するよう求めた。Metaは「ヨーロッパでのイノベーションやAI開発競争、人々へAIの恩恵をもたらすことの更なる遅れにつながる」と批判しつつも、ヨーロッパにおける計画を中止した。 (*13)
X(旧Twitter)でも同様に問題が指摘された。Xは、現オーナーであるイーロン・マスク氏が所有するAI開発企業xAIが開発した生成AIチャット「Grok」を搭載しているが、これと関連して2023年8月にユーザーが投稿したデータを生成AIの学習に使うと明確化する規約改定を行っていた。これらの動きに対しアイルランドデータ保護委員会は、アプリ内で学習データとしての拒否設定をデフォルトでオンにしていたことや拒否設定の提供が迅速でなかったことなどを挙げ、ユーザーデータの無許諾利用はGDPR違反であると指摘した。これに対しXは「X社がデータの透明性について努力しているのに対し、多くの企業はプライバシーを考慮せず公開情報を使っている。委員会が求めた命令は不当だ。」と抗議しながらも、2024年8月にEU内における個人データを利用するAIのトレーニング停止に合意した。(*14)(*15)
ヨーロッパ圏以外でも生成AIトレーニングにおける個人データの無断利用は問題視されている。ブラジルでは、先述したMetaが運営するSNSのユーザー投稿データをAIのトレーニングに利用するという2024年6月の発表に対し、同国のデータ保護機関ANPDが利用の停止を求めた(*16)。オーストラリアでも、2024年9月に行われた議会の公聴会で、2007年以降にMeta運営のSNSへ投稿されたユーザーデータを利用していることが同社の担当者への質問で判明している。(ただしオーストラリアにはEUのような強力な個人情報保護の法律がないため対応が難しいとされている)(*17)
生成AIトレーニングへ個人データを利用する事は、国家機関のみならず個人レベルでも問題視されており、関連する訴訟がいくつか起きている。
アメリカでは、2023年6月に個人情報を同意なく取得しておりプライバシー法に違反しているとして、OpenAIが匿名の個人複数人から提訴された(*18)(*19)。2025年1月には、米ビジネス向けSNS「LinkedIn」の運営を被告として、同社が無断でプライベートな電子メールの一部を複数の第三者に開示したのは違法であるとして、LinkedInのユーザーが訴訟を提起した。これに対しLinkedInは、「根拠のない主張だ」と争う姿勢を見せている。(*20)
アメリカでは、2023年6月に個人情報を同意なく取得しておりプライバシー法に違反しているとして、OpenAIが匿名の個人複数人から提訴された(*18)(*19)。2025年1月には、米ビジネス向けSNS「LinkedIn」の運営を被告として、同社が無断でプライベートな電子メールの一部を複数の第三者に開示したのは違法であるとして、LinkedInのユーザーが訴訟を提起した。これに対しLinkedInは、「根拠のない主張だ」と争う姿勢を見せている。(*20)
生成AIのトレーニングにユーザーデータを無断で利用する事に対しての批判がある中で、AI開発促進などを意図してむしろ個人情報を利用しやすくしようとの動きもある。
日本では、2025年2月頃から個人情報保護委員会によってAI開発を含む統計作成の用途においてのみ「要配慮個人情報」と規定されている人種・信条などの情報の利用を原則本人同意を求めなくても良い方向で法改正を進めている。この背景にはAI開発用途に取得した膨大なデータの中から個人情報を探し出し削除するのは現実的ではないとの声が事業者から上がっているためだという。違反した場合には課徴金を科す予定。(*21)(*22)
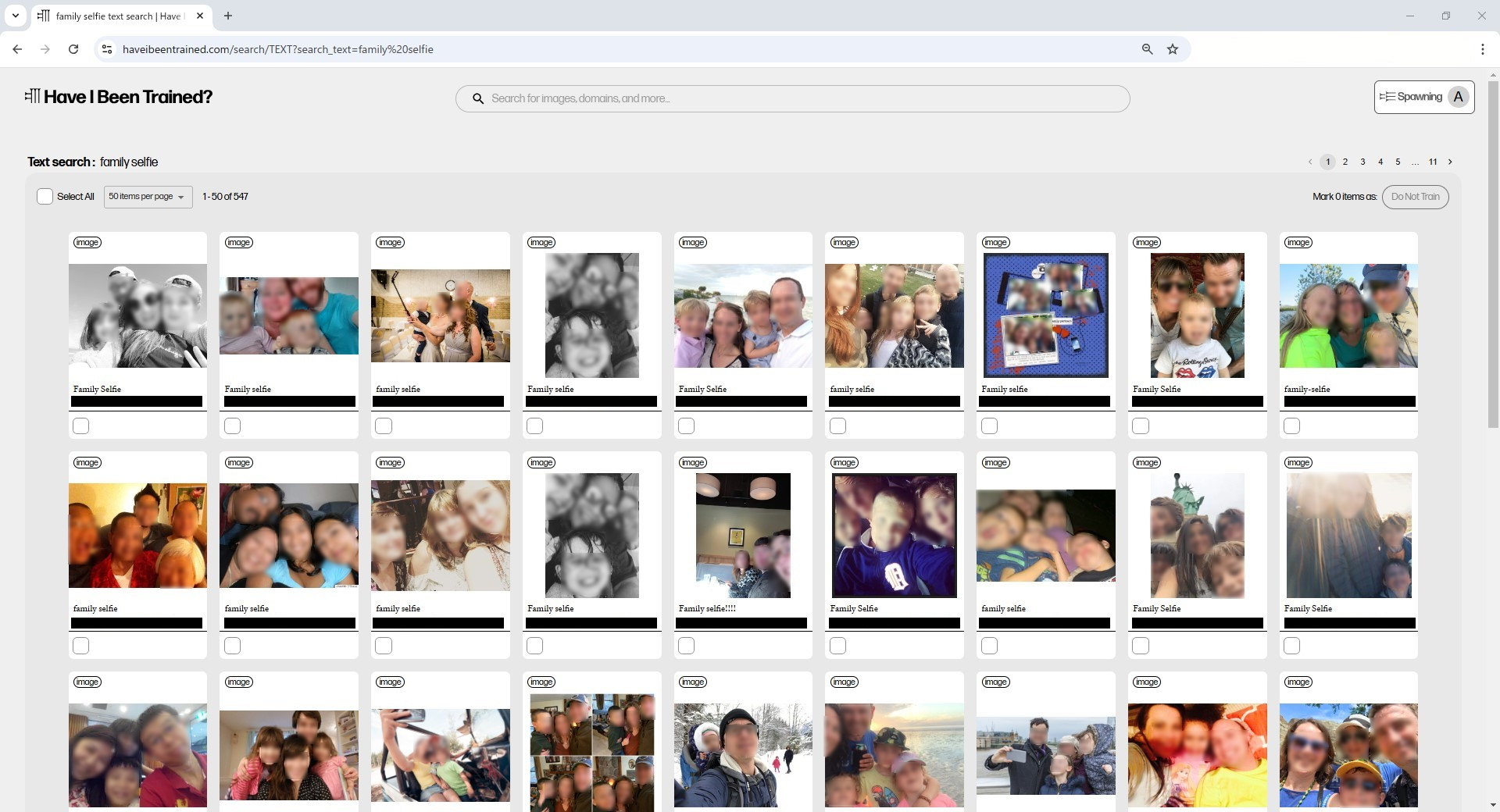
▼有名な画像生成AI「Stable Diffusion」などで利用されたデータセット「LAION-5B」内のデータを見ることの出来るサイトである「Have I been trained?」で「family Selfie(家族 自撮り)」と検索した結果。フリー素材と思わしきものもあるが、明らかに個人が撮影したように見える写真も多い。顔へのモザイクは当Wiki編集者が追加。

②ポルノコンテンツなど不適切データの利用
そして、特に画像生成AI開発用などに用いられるデータセットに関してポルノ画像、児童の画像(*23)や遺体画像といった不適切なデータが収集されたケースもあり、これも問題視されている。何が問題か、それは不適切なデータを開発に利用する過程を経てリリースされた生成AIは、不適切な要素を持つAI生成コンテンツを出力可能であることだ。例えば、開発時にポルノコンテンツを利用した場合は、AI製のポルノコンテンツが出力可能となる。さらに、特定人物やキャラクターの出力を目的としたLoRA技術などを用いれば実在人物に容姿を寄せたAIポルノ画像、実際の写真の一部を性的に加工したいわゆる剥ぎコラなどいったコンテンツが比較的簡単に作成可能なことが確認されており、生成AIを悪用した被害に拍車がかかっている。
具体的なケースとして、有名な画像生成AI「Stable Diffusion」などの開発に利用されたデータセットである「LAION-5B(独AI非営利団体LAIONが構築)(*24)(*25)」では、Stable Diffusionのリリース後にスタンフォード大学の研究によってCSAM(児童性的虐待コンテンツ、いわゆる児童ポルノ)が発見され(*26)(*27)、それらCSAMなど不適切なデータを取り除いたデータセット「Re-LAION5B」が公開される(*28)こととなった事件などが挙げられる。
例として挙げたLAION-5Bの他にも様々なデータセットが存在しているものの、データセット構築の際利用したテキスト、画像などといったデータが公開されているケースは少なく、自身が作成したデータが利用されていたとしても外からの確認が困難な事が問題視されている。
もちろん、不適切なAIコンテンツの出力を防止すべくAI企業側も入力できるプロンプトの種類を制限するなどといった対策を行っているが、「脱獄」と言う企業側の対策の裏をつこうとする行為が絶えない。この現状に対し、そもそもAI企業側がデータセットから不適切なデータを出来るだけ取り除く努力をすべきではなかったのかという指摘もある。
③クリエイター・権利者が権利を有するデータの無断利用
さらには個人データだけではなく、クリエイターの作品を生成AI開発のために無断で収集していることも問題となっている。
クリエイター関連では記事、小説、イラスト、写真、音楽、声など、クリエイターが製作した作品のデータを無断収集する過程があった、またはあったとされる生成AI製品やその開発企業に対しての反発が高まっている。また、これらのデータ収集に海賊版サイトや無断転載サイトが利用されていることも批判されている。
海賊版や無断転載サイトの利用例として、先述のStable Diffusionをベースに美少女・アニメ系AIイラストの出力に特化させた画像生成AIモデル「NovelAI」が無断転載サイトである「danbooru」を利用していた(*29)こと、米Meta(旧Facebook)が開発した大規模言語モデル「LLaMA」において、海賊版書籍などを含むデータセット「LibGen」を利用していたことが作家らとの裁判で判明した(*30)ことなどが挙げられる。
この構造に対し、クリエイターサイドからは「AI企業は作品データを同意なく無断収集した上で生成AIを開発、そのAIから出力されたコンテンツが作品データを使われたクリエイターらと市場競合し、クリエイター側は経済的苦境に追い込まれる」という批判が大きく、「AI企業からクリエイターなどへの一方的な搾取構造だ」と指摘されることもある。
一方で、生成AIを開発するAI企業の中には「人々が楽しめる新しいコンテンツを大量提供しクリエイターにお金を払わなくてもよくなる」(*31)事を開発の目的であると示す企業もいるため、(クリエイターの作品等を生成AI開発に無断利用しているという構造を鑑みれば)目的の根本的部分からクリエイター側と対立することを避けるのは難しい構造である。
この構造を批判する意見や声明などが国内外を問わずクリエイター個人や業界団体などから多く出ており、海外ではAI企業との訴訟に発展したり、生成AIを利用したい雇用主と労働者の間でストライキが起こる事態にもなっている。
一例として、2023年にアメリカの脚本家団体である全米脚本家組合(WGA)と俳優・声優団体である全米映画俳優連合(SAG-AFTRA)がAI利用のルール整備や報酬などを巡り合同でストライキを起こしたり(*32)(*33)、米紙ニューヨーク・タイムズがChatGPTの開発会社であるOpenAIに対し生成AI開発への記事の無断利用を主張し訴訟を提起したケース(*34)やユニバーサル・ミュージックなど米国の音楽レーベルが音楽生成AI開発企業に対し同様に音楽の生成AI開発へ無断利用したのではないかと主張し同様に提訴したケース(*35)が挙げられる。
国内でも音楽著作権管理団体である日本音楽著作権協会(JASRAC)(*36)やメディア団体である日本新聞協会(*37)などといった様々な団体・企業などが生成AI開発の現状に懸念を示す声明を出している。
- ⇒団体の声明などは「生成AIに対するクリエイター団体・企業などの反応・対応」へ。
- ⇒権利者とAI企業の裁判は「生成AIに関する訴訟・法的対応一覧」へ。
法的な扱い
生成AIの開発時に著作物を無断利用することについて、法的にはどうなっているのだろうか。
日本国内においては、著作権法の2009年改正で新設された「著作権法旧47条の7」を置き換える形で2018年に改正された「著作権法30条の4」が「当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」に当てはまり、「当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合」に当てはまらないのであれば「AI開発に著作物を無断利用してもよい」根拠とされている。
しかし、2022年ごろから生成AIの無秩序な開発・公開によってクリエイターや権利者が一方的に損害を受ける状況となったことで、「現状と合っていない」として同法の改正もしくは解釈変更をすべきとの主張が国内の権利者団体やクリエイターなどから為されている。(*38)
しかし、2022年ごろから生成AIの無秩序な開発・公開によってクリエイターや権利者が一方的に損害を受ける状況となったことで、「現状と合っていない」として同法の改正もしくは解釈変更をすべきとの主張が国内の権利者団体やクリエイターなどから為されている。(*38)
OpenAIやGoogleなど、世界的IT企業の拠点であり生成AI開発も盛んなアメリカでは、生成AI開発時の著作物の無断利用が、アメリカ著作権法に定められたルールであり一定の条件下であれば著作物の無断利用を可能とする「フェアユース(Fair Use)」にあたるのかが争点となっている。同国において多数提起されている権利者を原告としAI企業を被告とする著作権訴訟でもよく取り上げられている。
1-2.現状に対する解決案
これらデータ収集段階に関する問題の解決方法として「データ利用料の支払い」「データ利用を許諾制にしたり拒否できる制度・機能の設置」などといった案が提唱されている。
しかし、これらの案も様々な問題があるため実現にはほど遠い。
⇒「クリエイター関連で提唱されている生成AI規制案」も参照。
しかし、これらの案も様々な問題があるため実現にはほど遠い。
⇒「クリエイター関連で提唱されている生成AI規制案」も参照。
案1:データを利用したら対価を支払う?
まず、「利用データに対して対価を支払う」という案だが、これには「基盤モデルへ利用したデータへの還元」と「特化モデルへ利用したデータへの還元」の二つが提唱されている。
基盤モデルとは大量のデータを集めた上で構築されたAIモデルの事を指し、特化モデルとはその基盤モデルへ特定の傾向を持ったデータ群を追加してその傾向に関するAI生成物を出力させることに特化したモデルの事を指す。特化モデルの一種とされるのがLoRAである。
しかし、これらに対して提案されている還元案には様々な問題が指摘されている。
- 基盤モデルで利用したデータへの対価還元
一番の問題点として挙げられるのは、生成AI開発のために利用しなければならないデータがあまりに多すぎるという点だ。
有名な画像生成AI「Stable Diffusion」などで利用されているデータセット「LAION-5B」はなんと約58億もの画像とテキストのペアを含んでおり、Instagramの運営などで知られるIT企業Metaが開発した大規模言語モデル「LLaMA」でも利用されているデータセット「Books3」は約19万冊もの書籍から構成されている。(*39)(*40)
そのため、還元するとしても天文学的な額になると考えられており、現実性が高い案とは言いにくい。
なら生成AIに利用するデータの数を減らせばいいのではないかと思えるが、開発時に利用したデータの数や質、多様性に生成AIが出力したコンテンツの質も依存する度合いが高いとされているため、これも難しい。
さらに、還元をすると仮定した場合その主体として真っ先に想定されるAI開発企業も「技術開発が出来なくなる」などとして還元には積極的ではない。(*41)。しかしながら、ChatGPTの開発企業であるOpenAIが欧米諸国のメディアに記事利用料の支払いを行うなど、少ないながら還元の動きもある。(*42)
これとは違う方向性として、生成AI開発用コンテンツを作成する業務を高学歴ギグワーカーなどに委託する「ネットにあるデータを無断で使うのではなく、専門知識を持つ者などにデータ作成を依頼する」ケースも見られている。(*43)
一方で、生成AI開発企業から画像データの購入を提案されたが、1枚数十円程度と極端に安い額を提示されたとの事例も存在する。(*44)
これとは違う方向性として、生成AI開発用コンテンツを作成する業務を高学歴ギグワーカーなどに委託する「ネットにあるデータを無断で使うのではなく、専門知識を持つ者などにデータ作成を依頼する」ケースも見られている。(*43)
一方で、生成AI開発企業から画像データの購入を提案されたが、1枚数十円程度と極端に安い額を提示されたとの事例も存在する。(*44)
- 特化モデルに対する対価還元
生成AIモデルには上記のような大量のデータを集めた上で構築される「基盤モデル」のほかに、特定の傾向を持った少量のデータを基盤モデルに取り込んで追加でAI学習を行い、その特定のデータに関するコンテンツなどを出力させる「ファインチューニング(*45)」を行った「特化モデル(LoRAなど)」がある。この二つはゲームソフト本体とmodの関係などで例えられることがある。
特化モデルは、クリエイターと生成AIの文脈において、特定の人物やキャラクター、イラストレーターの画風といった個々のクリエイターが持つ個性を模倣し、出来るだけそれに近い要素を持ったAIコンテンツを出力させる際に利用される。クリエイター側からは特に後者である「特定のクリエイターの個性を模倣した特化モデル」が問題視されている。
この個性を模倣した特化モデルについてクリエイターへの還元を行おうとの提案があり、これは基盤モデルへの還元よりは現実性が高いとみられている。これを行うメリットとしては、「正規版を販売する事で現在流通している海賊版特化モデルを駆逐する事ができる」「不正競争防止法などで処罰できる可能性がある」などとされる。国内では漫画家で国会議員を務める赤松健氏が特化モデルに基づく還元を提唱したほか、声優においても自身の声をコピーしたAIモデルを販売する動きもある。
ただし、これにも問題が指摘されており「特化モデルとはいえ、クリエイター本人との市場競合の可能性なども考慮すれば、それなりに大きな額が必要になると考えられるため、AI企業側の支払い能力に疑問が残る」「関連する法整備なども同時に行わなければ海賊版の駆逐のような想定した効果が得られないのではないか」といった点だ。(提案されている規制案、学習データとなった作品の作者に対価を の項目も参照)
また、「基盤モデル」と呼ばれる物でも、特定のクリエイターの作風などを真似た生成物を出力可能な場合もあるため、「基盤モデル」と「特化モデル(追加学習/LoRA)」を分ける意味は実質的に無いのではないかとする指摘もある。(*46)(*47)
案2:データ収集を許諾制に&データ利用拒否制度・機能を設置する?
次に、「データ利用を許諾制にしたり、拒否制度・機能を設置する」案だが、生成AI関連では前者が「オプトイン」後者が「オプトアウト」と称されている。
「オプトイン」とは、「作成者・権利者から許諾を得たデータのみを生成AI開発に利用でき、利用を拒否しているデータや許諾について何らかの表明を行っていないデータは利用不可」という形態のことである。
これは権利者側にとって有利な方式であり、クリエイター団体が会員のクリエイターらに向けて行ったアンケートでも90%以上が支持している。(*48)(より正確に言えば「利用許諾を取ったデータのみで生成AI開発をすべきか」という質問への賛成数。)
一方で、AI開発側からすれば利用できるデータが減ったり、許諾を得る手間などがかかったり、利用可能なデータの減少によるAI生成コンテンツの質低下などのデメリットがある。
一方で、AI開発側からすれば利用できるデータが減ったり、許諾を得る手間などがかかったり、利用可能なデータの減少によるAI生成コンテンツの質低下などのデメリットがある。
反対に「オプトアウト」とは「基本的に無許諾でインターネット上のデータを生成AI開発に利用可能だが、利用を拒否したデータのみは不可」という方式である。
これは拒否されたデータ以外は使用してもいいという方式なので、相対的にAI開発側が有利である。
そして「拒否意思を示せば利用されない」という特性上、権利者側にとっても利益があるようなシステムに一見見えるが「何をもってしてオプトアウトが成立したといえるのかの不確実さ」「オプトアウトシステムの存在が多くの人に対して伝わらないのではないか」「オプトアウトがどのような方式を取られるかによっては、権利者側の負担が大きくなるのではないか。特に個人クリエイターなどへの負担が重たくなるのではないか」などといった複数の問題が指摘されている。(提案されている規制案、オプトアウトの項目を参照)
そして「拒否意思を示せば利用されない」という特性上、権利者側にとっても利益があるようなシステムに一見見えるが「何をもってしてオプトアウトが成立したといえるのかの不確実さ」「オプトアウトシステムの存在が多くの人に対して伝わらないのではないか」「オプトアウトがどのような方式を取られるかによっては、権利者側の負担が大きくなるのではないか。特に個人クリエイターなどへの負担が重たくなるのではないか」などといった複数の問題が指摘されている。(提案されている規制案、オプトアウトの項目を参照)
EUなど一部の国と地域では、データ利用拒否の手段としてオプトアウトを選択しようとしているが、もし今後オプトアウトが世界的主流になるのであればどのような形式になるのかが権利者、AI企業双方にとって重要だろう。
案3:robots.txtなどのツールを利用してサイトへのクローラーのアクセスをブロックする?
より現実的なデータ利用拒否の方法として「robots.txt」の存在がある。
インターネット上のウェブサイトから自動的にテキストや画像などのデータを集めるボットとしてウェブクローラーがある。また、その技術のことや集めることをクローリングまたはスクレイピングと呼ぶ。この技術は検索エンジンにおいて欠かせない技術とされる一方、生成AI開発用のデータ集めにも使われている。
robots.txtは、そのウェブクローラーのアクセスをウェブサイト側がどの程度受け入れるか選択することができる技術である。
robots.txtは、そのウェブクローラーのアクセスをウェブサイト側がどの程度受け入れるか選択することができる技術である。
報道機関のサイトを中心に、robots.txtなどを用い生成AI開発用ウェブクローラーのアクセスを拒否する措置を行うサイトが多く見られており、生成AI登場後にデータアクセス制限を行うウェブサイトが急増したとの調査もある。(*49)
robots.txtなどクローラーのアクセスを拒否するツールの活用については、日本国内の政府有識者会議でも問題の解決手段として推奨される(*50)など、権利者とAI企業間の「紳士協定」に出来ないかと期待する声がある。
しかし、AI企業がサイト側によって設定されたrobots.txtを迂回しアクセス拒否されたクローラーとは別のクローラーを用いデータ取得を試みたことが報道されるなど、robots.txtを用いてクローラーをブロックするという手段は機能していると言い難いのが実情だ。
しかし、AI企業がサイト側によって設定されたrobots.txtを迂回しアクセス拒否されたクローラーとは別のクローラーを用いデータ取得を試みたことが報道されるなど、robots.txtを用いてクローラーをブロックするという手段は機能していると言い難いのが実情だ。
具体的な事例として、米Anthropicが別のクローラーを利用しておりデータ収集を回避出来ていないと指摘されたケース(*51)、米Perplexityがクローラーをブロックしているサイトのrobots.txtを無視しアクセスしていたケース(*52)などが挙げられる。
robots.txtと同様にクローラーのアクセスを抑止する事を目的としたツールとして、米インターネットセキュリティ企業Cloudflareが発表した「AI Labyrinth」が存在する。AI LabyrinthはAI生成された偽のページにクローラーを誘導し、時間とリソースを消費させるというものであり、robots.txtとは毛色が異なる技術である。(*53)(*54)また、個人のプログラマーが開発した同様のツールとして「Nepenthes」がある。(*55)
その他
上記の案の他にも、様々な解決案が出されている。
技術的な解決方法として、人間が作成したデータを利用するのではなくAIが生成した「合成データ」を利用する案(*56)、AIモデルの中から特定のデータを削除するマシン・アンラーニング技術(*57)(*58)などもあるが、いずれも確実なものとはなっていない。
作品の発表場所にネットを用いず、例えば紙の本のようなアナログな手段にすべきという意見もある。しかしながら、ネットでの広報活動の重要性からクリエイターが離れる決断をするのは現実的には難しい事や、アナログな手段を使い作品を発表したとしても第三者が勝手にデジタルデータ化してネットへアップロードし、それをAIクローラーが拾ってしまえば何の意味もない。
その他にもクリエイターとAI開発企業がどのような方法で決着するか、様々な案が出されているが、現状の生成AIの構造やAI開発側とクリエイターのそれぞれの考え方の違いや利益・負担などを原因として一向に進んでいないのが現状だ。
特に画像生成AIなどでは、クリエイターの作品だけではなく一般人がインターネットに上げた自撮り写真といった個人のデータも含まれるため、これについても還元をするのか?データを利用拒否できるようにするのか?そもそも無断で使っても問題ないのか?といった論点も残されている。
⇒クリエイター関連で提案されている規制案などについては「クリエイター関連で提唱されている生成AI規制案」へ。
⇒クリエイター関連で提案されている規制案などについては「クリエイター関連で提唱されている生成AI規制案」へ。
【2. 偽情報・コンテンツの作成・拡散】
生成AIは、デマ情報等の作成にも利用されている。デマ情報の作成において、既に何度か生成AI(特に画像生成AI)によって作られたデマが作成・拡散される事例が発生するなど事態は深刻化しつつある。また、パブリックコメントといった政策に対する意見の場において、特定の思想などに偏った意見が少人数によって大量に送られるなどの事態も起きており、議論の場が機能しなくなる可能性も指摘されている。
なお、本項目は「人間が意図的に悪意を持って生成AIを利用したケース」のみをまとめている。人間の悪意こそないが生成AIの技術的特性などを原因として起こる「ハルシネーション(生成AIが自信たっぷりに間違った回答をする問題)」とそれに関する問題は「6. ハルシネーション(幻覚)問題」へ。
2-1. 画像生成AIのフェイク
生成AIが本格的に普及する前は、誰かが撮影しインターネット上にアップロードした写真などを用い、(コラージュなどの工程も経て)元写真が撮られたときの実際の状況とは違うキャプションなどを付けネットに放流する、というのがデマ作成の方法として一般的なものであったと思われる。
しかしながら、画像生成AIは基本的には既存の画像とは見た目上異なる画像を出力するため、以前のようにブラウザの画像検索機能を用いたり人間の記憶を辿ったりする等で元画像のありかを探してデマであることを証明する、という行為が著しく困難になる。しかも、画像生成AIの精度は日進月歩で進化しているため、以前は画像生成AI製画像の大きな弱点として指摘されていた手や指の形状の不自然さも克服されるなど、だんだん人間の目ではAI製フェイク画像を見抜くことが難しくなっている。
画像生成AI普及以前において精巧なコラージュ画像を作るには高度な画像編集技術が必要であったが、画像生成AIは技術の無い人でもAIに作って欲しい画像についてプロンプト(リクエスト文)を打つだけで誰でも精巧なフェイク画像を作ることが出来る点にも留意しなければならない。さらに音声や動画生成系のAIも日々発達しており、音声や動画系の情報にも警戒する必要がある。
この状況に対しアメリカや欧州の政府は生成AIを提供する企業などに対し対策を求めるなど、政治レベルでの動きを活発化させているがまだまだ道半ばである。
【画像生成AIを用いたデマの代表例】
- 2022年9月:静岡県などを襲った台風15号による災害が起きた際に作成・拡散された。あるツイッター(X)ユーザーが画像生成AIを用いて街全体が浸水している様子を空から取った画像を作成。これを「ドローンで撮影された静岡県の水害の様子」との内容のキャプションを付け投稿した。
・静岡県の水害巡りフェイク画像が拡散 画像生成AIを利用 投稿者はデマと認めるも「ざまあw」と開き直り(2022年9月26日-ITmedia) - 2023年3月:画像生成AIサービスMidjourneyのユーザーが作成した「アメリカの前大統領ドナルド・トランプ氏が警察官に連行されるフェイク画像」が投稿、Midjourney運営は当該ユーザーを利用禁止処分とした。
・画像生成AI「Midjourney V5」を利用して偽の「トランプ前大統領が逮捕された」画像を生成した人物が利用禁止処分を受ける(2023年3月23日-GIGAZINE) - 2023年5月:「ペンタゴン付近で爆発が起きた」との内容のフェイク画像が作成、拡散された。この画像は有名メディアの公式ツイッターを装った偽アカウントで投稿されるという巧妙さであった。幸いすぐにフェイク画像であると広まった為大きな被害はなかったものの、アメリカの株式市場において売り注文が殺到するという事態が発生した。
・AIが生成したペンタゴン爆破の偽画像で米株式市場が大荒れするまで(2023年5月26日-GIZMODO)
2-2. 音声生成AIのフェイク
【音声生成AIを用いたデマ・出来事の代表例】
- 2023年1月:ElevenLabsがβ版として無料公開した音声生成AIにより、著名人らの偽音声の作成が相次いだ。
・新たなAI音声生成ツール、公開直後から著名人の声でヘイトスピーチや不適切発言させるディープフェイクボイスが横行(2023年2月1日-TechnoEdge) - 2023年2月:ニュースサイトのライター・ジョセフ・コックス氏が、無料で使える音声AI(ElevenLabs)を使って自分の銀行口座にアクセスできたことを報告。
・無料で使えるAIが生成した声で銀行口座への侵入に成功したとの報告(2023年2月24日-GIGAZINE) - 2023年5月:マカフィー株式会社、日本を含む世界7ヵ国を対象にしたオンライン音声詐欺に関する調査報告「The Artificial Imposter」を発表。
・AI(人工知能)を悪用した音声詐欺が世界で増加中(2023年5月17日-PR TIMES) - 2024年2月:生成AIにより作成されたとみられる「ジョー・バイデン大統領の声で予備選に投票しないよう呼びかける自動音声電話」が約5000~2万5000件発信され、発信元として特定された企業・プロバイダーに対し刑事捜査通告がなされた。
・AI製「偽バイデン」の電話、発信元はテキサス州企業 犯罪として捜査(2024年2月8日-Forbes)
2-3. パブリックコメントなど政策議論の場における少人数での大量投稿
政府が行おうとしている政策や立法などについて、国民が意見を送付できる制度として「パブリックコメント(パブコメ)」がある。パブコメにおいて、テキストを生成するAI(ChatGPT等)を悪用し特定の方向に偏った意見を大量投稿するという事案が発生。この事によって、政策議論の場が機能不全となったり、職員の負担増などの問題が起きると考えられる。
【パブコメにおいて生成AIが悪用された事例】
- 2025年2月:経済産業省が募集したエネルギー基本計画のパブリックコメントへ、生成AIを利用したとみられるコメントが投稿される。AIで作成されたコメントは全体の1割ほどとみられ、10件以上投稿した46人だけで計3940件の意見を送付していた。一人の最大投稿数は457件にものぼる。この基本計画は原発の活用を最大限進めるもので、AI作成のコメントは大半が反原発関連のものであった。
・AI利用で4千件投稿か エネルギー基本計画の意見公募 46人で全体の1割、反原発大半 (2025年2月20日:産経新聞)
・大半は反原発…生成AI使い46人が3940件の“パブリックコメント”を政府に大量投稿 原発“最大限活用”打ち出したエネルギー基本計画(2025年2月20日:FNNプライムオンライン) - 2025年3月:仙台市が募集した宿泊税に関するパブリックコメントにおいて、投稿された420件のうち2割にあたる約80件がAIで作成したものであると判明したケース。
AI作成の大量投稿に苦慮(2025年3月11日:新潟日報)
【3. AI製ポルノ・AI製児童ポルノ】
生成AIは、ポルノや児童ポルノの作成にも利用される。この項目では画像生成AIで作成されたポルノ、特に写真風のリアリスティックなAI製ポルノをメインに記述する。
3-1. AI製ポルノ問題
2023年現在、生成AI(特に画像生成AI)で作られたポルノが大量に作られ、インターネット上にアップロードされている。それらの中には有名人(特に女優・女性アイドルなど)の容姿を模したものも出回るなど(当然無許可)、状況は深刻化している。有名人か一般人か、ネットに自撮り写真をアップしているかしていないかにかかわらず、この問題に巻き込まれる可能性がある事に注意しなければならない。
まず、画像生成AIを用いたポルノは主に以下の3つの種類に分けられる。
- 1.有名人・一般人を問わず特定人物の顔立ちへ意図的に寄せたもの
- 2.既存の写真の一部を生成AIを用い性的に加工したもの
- 3.特定人物の顔立ちなどには意図的に寄せていない、ただプロンプトなどを打ってポン出ししたもの
1は、ネット上に顔出し写真をアップしているだけでも他人が勝手に自分の顔立ちに寄せた偽ポルノを作ることが出来てしまい、そのクオリティによっては偽ポルノであると証明する事も困難になり、社会的・精神的なリスクが付きまとう。2についても同様で、1に比べれば元写真が存在する分まだ偽物である事の証明はしやすいものの、同様のリスクが残る。3については自分の顔が写った写真がデータセット(※画像などの大量のデータを一つにまとめたもの)内に入っていれば、偶然自分に近い顔立ちの人が描写されたAI生成物が出てくるかもしれない。
では、なぜこのような状況になったのか?その根本的な問題は一つの企業にある。2022年後半、Stability AIという英国の生成AI開発スタートアップ企業が「Stable Diffusion(ステーブル・ディフュージョン・以下SD)」という画像生成AIをリリースした。SDはドイツのAI関連非営利団体LAIONが作成した「LAION-5B」と呼ばれる約58億枚の画像データが入った画像データセットを用いて開発されたが、LAION-5Bはポルノや児童ポルノ、暴力的な画像、個人情報に関連する画像など倫理的に問題のあるデータを排除する取り組みが不十分なままであり、SDにもそれらが反映されることとなった。しかもSDはオープンソースでリリースされたため、SDをベースとした派生の画像生成AIサービスが世界中で多く存在している。
SDリリース時の倫理チェック体制の甘さのみならず、問題を深刻化している要素はもう一つある。ネット上のいち個人が作成したLoRAなどの追加学習モデルだ。これらはSDで動く。SDと追加学習モデルの関係性は例えるなら、テレビゲームにおけるゲームソフトとDLC(ダウンロードコンテンツ)やModの関係性に近い。つまり元々のモデルに特定の要素を追加し、より希望に近い画像を出力させるのである。特にLoRAは、有名人の写真を無断でAI学習させ、それらがインターネット上の共有サイトにおいて多数にダウンロードされるという事態が現在進行形で発生しており、問題視されている。
これらの問題は、Stability AIが偽ポルノ画像・フェイク画像天国となる可能性があったにも関わらず、不適切なデータの精査・除去なしにオープンソースでリリースしてしまったことに起因している。反対に、Photoshopを代表するクリエイティブツールの開発で知られるAdobe社が開発した画像生成AI「Firefly(ファイアフライ)」では、オープンソースにしてネットに放流するような事はせずあくまで既存のAdobe製ソフトに組み込む形でリリースされ、不適切なデータは開発段階である程度除去され、フェイク画像などが作れない様プロンプト(リクエスト文)には単語の制限をかけるなど、画像生成AIを不適切な形で使われない様一定の配慮が為されている。
なお、Stability AIは不適切なデータを排除した「Stable Diffusion 2.0(SD 2.0)」をリリースしているが、SDはWebサービス版だけではなく個人のPCで動かせるローカル環境版も存在するため、余り現状の回復には貢献していないのではないかという主張もある。
今までの文章を読んで「有名人だけでしょ?自分は関係ないよ」と思う方もいるかもしれないが、一般人の被害も実際に起きている。現にSNSに自らの制服姿の自撮り写真を上げた若い女性に対し水着を着せる加工や妊娠しているかのように見える加工が画像生成AIで行われた事例もある。⇒この問題についてのTogetterまとめ。【実際の画像も出てくるので閲覧注意!】
これに対して「SNSに顔出しするのはリスクがあるし仕方がない」という意見を持つ人もいるかもしれないが、何も自らの意思で撮った自撮り写真だけがAI加工の対象となるわけではなく、盗撮写真であったり、一見撮影者に悪意がないように見える状況で撮影された写真においても写真データさえあれば、特定個人の顔立ちに寄せた偽ポルノ画像であったり、既存の写真を違和感が少ない状態で性的な加工をする事が容易に出来るようになってしまった。
性的な目的だけではなく、嫌がらせ目的で偽ポルノを作る可能性も当然考えられる。それらが実際に社会においてどのように悪用されるのかはすぐに想像できる。
3-2. AI製児童ポルノ問題
生成AI(画像生成AI)で実際の児童ポルノのようなフォトリアルな画像を作ることも出来る。画像生成AIで作ったフォトリアルな非実在児童の性的画像についてはいわゆる「児童ポルノ」に当たるかなど、法的解釈が定まっていない部分もあるが、このページでは分かりやすく「AI製児童ポルノ」と表記する。
AI製児童ポルノは「基本的に出力されるのは非実在児童だが、実在児童の写真データをAI学習元として使っている。」という極めてややこしい特性を持つ(これは児童に限らず成人でも同じだが)。「いくら学習データに実在児童を使っていたとしても出力されるのは顔立ちなどが違う別人なので問題ない」という主張もあるが、画像生成AIが偶然実在人物に酷似した顔の人物を出力した事もあるため、必ずしも全てに適用できるものではないだろう。
AI製児童ポルノを肯定する人の中には「AI製児童ポルノの登場によって小児性愛者がAI製で満足し実在児童の被害が減る」という主張をする人もいるが、効果があるのかは現状定かではない。
しかしながら、AI製児童ポルノがもたらす明確な問題も存在している。それは「AI製児童ポルノが大量にネット上に氾濫する事で、実在児童が被害者となっている本物の児童ポルノの捜索に悪影響を及ぼしている」というものである。これらの問題は既に捜査機関や児童ポルノ対策団体から指摘されている。画像生成AI「Stable Diffusion」を運営するStability AIはAI製児童ポルノの作成を止めるため、トレーニングデータから問題のあるものを削除し、作成能力を低下させるなど画像生成AI開発企業もある程度の対策を行っているが、これは確実なものではない。
関連記事1⇒「英国版FBIが警鐘、生成AIによって摘発が困難になる児童ポルノの深い闇」(2023年7月22日-JBpress)
関連記事2⇒「AI-generated child sex images spawn new nightmare for the web」(2023年7月19日-ワシントンポスト)
関連記事3⇒「生成AIの児童性虐待画像を売買 日本のソーシャルメディアなどで」(2023年6月28日-BBC日本語版)
関連記事2⇒「AI-generated child sex images spawn new nightmare for the web」(2023年7月19日-ワシントンポスト)
関連記事3⇒「生成AIの児童性虐待画像を売買 日本のソーシャルメディアなどで」(2023年6月28日-BBC日本語版)
【4. デジタルデータの信頼性が低下する可能性】
生成AI製のコンテンツが溢れることによって、電子的なデータの信頼性が崩れることも憂慮されている。
主に詐欺での使用や司法の場における証拠データの信頼性低下の可能性、疑惑のある人物が明確な証拠物が出てきたとしても「これはAIで作られたものだ」と言ってしまえば疑惑から逃れられてしまう可能性、もしくは全く無実な人が偽のAI生成物によって罪をでっち上げられてしまう可能性が問題視されている。
4-1. 詐欺への使用
詐欺については音声生成AIを悪用したものがある。それらを利用した詐欺として、「知人を偽り困窮していると嘘をつく」「被害者の連絡先に電話をかける」といった行為がある。
セキュリティソフトで知られるマカフィーが実施した音声生成AIを悪用した詐欺の被害調査では、日本、米国、英国、ドイツ、フランス、オーストラリア、インド7か国の7054人を対象として実施し、「自身、もしくは知人がAIによる音声詐欺に遭遇した事があるか?」という設問に対し、「自身が遭遇」「知人が遭遇」を選択した人は世界平均でそれぞれ10%と15%となった。中でもインドは突出して多く20%と27%という結果であった。同調査においてはAIで作られた音声を識別できるかという設問に対し、「識別できるかどうか分からない」「識別できないと思う」との回答が35%ずつで合計70%となった。この調査においては日本のAI音声詐欺の遭遇率は低かったものの、マカフィーの担当者は「日本は音声データの共有率が低くその分詐欺に遭遇する事が少なかったが、今後遭遇する可能性が高いとも受け取れる。マカフィーの調査によればわずか3秒で85%の一致率を有する音声クローンが作成可能だ。現状を認識し音声の共有には慎重になり、音声詐欺の遭遇に備える必要がある」と述べた。
⇒マカフィーによる調査結果の詳細「AI(人工知能)を悪用した音声詐欺が世界で増加中」(2023年5月27日-PRtimes)
⇒マカフィーによる調査結果の詳細「AI(人工知能)を悪用した音声詐欺が世界で増加中」(2023年5月27日-PRtimes)
実際にアメリカでは、娘の声をAIで再現した上で母親に電話を掛けて偽の誘拐事件をでっち上げ身代金を要求するという事件が発生している。
⇒Traumatized Ariz. mom recalls sick AI kidnapping scam in gripping testimony to Congress(2023年6月14日-Newyork post)
⇒Traumatized Ariz. mom recalls sick AI kidnapping scam in gripping testimony to Congress(2023年6月14日-Newyork post)
4-2. 司法の場などにおけるデータ証拠信頼性低下の可能性
裁判の場において提出された証拠に対し、「これはディープフェイクだ」と主張するケースが見られている。本当にやった行為であってもそれそのものの存在がやった側に取って不利になるのならば当然「ディープフェイクで作られた偽の音声(あるいは画像・動画)だ!」と主張する。
2018年に起きたテスラ車の死亡事故において、「オートパイロット機能が誤作動した」と主張した遺族側に対しテスラ側は「ドライバー側の過失だ」と抗弁した。その中で、遺族側は同社のCEOイーロン・マスクが「テスラ車は人よりも安全に走行できる」と語った音声を証拠品として提出したが、テスラ側は「マスク氏はその有名さからディープフェイクの対象になりやすく、証拠映像の信ぴょう性に疑問がある」と主張する事態が発生した。
さらに今年4月には(裁判とは関係ないが)インド・タミル・ナードゥ州の政治家に対し「横領を行っている」と告発する内容の音声が流出。その政治家は「これは機械によって生成された」ととしたものの、実際の音声であると判明。
関連記事1⇒「裁判に提出された証拠映像に対して「これはディープフェイクだ」と反論する人々が登場することを専門家が懸念」(2023年5月9日-GIGAZINE)
関連記事2⇒「生成AIによるフェイクコンテンツとの戦いは、ウォーターマークが導入されても終わらない」(2023年8月7日-WIRED)
関連記事2⇒「生成AIによるフェイクコンテンツとの戦いは、ウォーターマークが導入されても終わらない」(2023年8月7日-WIRED)
【5. インターネットの汚染】
生成AIで作られた不正確なコンテンツによってインターネットの情報の正確性等が失われる可能性がある。既に画像検索においては、例えば動物の名前で検索した場合に、画像生成AIで作られた不正確な形状の動物の画像が出てくるとの報告が寄せられている。
5-1. 汚染の事例
実在する動植物の画像検索結果として、最優先(サジェスト)または上位を占める数、生成AI画像が表示された実例。
いくつかのサジェスト結果は修正されたものの、生成画像そのものが根絶された訳ではないため、いたちごっこなのが現状である。
いくつかのサジェスト結果は修正されたものの、生成画像そのものが根絶された訳ではないため、いたちごっこなのが現状である。
- 【虫画像注意】「トコジラミ マクロ」で画像検索したらAI生成写真ばかりになっていて草「これはヤバい」「紙の図鑑の価値があがる」(2023年12月5日:Togetter)
- 「これの恐ろしい所は、自分の関心ある領域ならおかしい事に気付くけど、あまり関心の無い分野であれば容易に偽物をつかまされる危険性が高い事」(2024年9月17日:x.com)
- AIによる画像生成、私たちの想像力の汚染(2024年12月:AOKIstudio)
5-2. 汚染問題への対策
インターネットやSNS上にAI生成コンテンツが大量に溢れ、収拾がつかなくなっている現状を改善すべく、テクノロジー企業が様々な技術を開発・実装しており、一部の国や地域では法律的にも対策が進みつつある。
技術的対策としては、AI生成コンテンツに電子透かし技術を施すことや、電子透かしなどの情報に基づきAI生成コンテンツであることをSNSなどサイトで表記するといったことが挙げられる。
ChatGPTで知られるアメリカのAI企業OpenAIは、画像生成AI「DALL-E3」に、データの来歴情報の標準化を策定する団体「C2PA」に基づく来歴情報データを埋め込むと発表。(*59)
Googleは前述の標準化団体C2PAに参加し、AI生成コンテンツにAI生成であると示すデータを付与する技術「SynthID」を発表、画像生成AI「Imagen」で生成した画像やチャットボット「Gemini」のテキストなど、Googleが開発したAI製品に順次適用される。(*60)
PhotoshopやIllustratorで知られるAdobeも自社の生成AIで生成したコンテンツに対し、C2PAと同様の標準化団体である「CAI」に基づいたAI生成と分かる来歴情報データを付与するとしている。(*61)
また、英国のAI企業StabilityAIも、2022年11月に発表された画像生成AI「Stable Diffusion 2.0」よりAI画像であると分かるデータを挿入できるようにしている。(*62)
とはいえ、これらの企業はフェイク対策技術を進める一方で、同時に生成AIサービスの開発・提供を行っている所も多い。マッチポンプ
昨今のAI生成コンテンツをめぐる混乱は、テクノロジー企業同士の苛烈な開発競争や悪用対策が不十分なまま開発だけは進んだこと、慎重に実装すべきである技術にも関わらず経済的利益などを目的に踏むべき過程を飛ばしてしまったのが原因とも批判される。
昨今のAI生成コンテンツをめぐる混乱は、テクノロジー企業同士の苛烈な開発競争や悪用対策が不十分なまま開発だけは進んだこと、慎重に実装すべきである技術にも関わらず経済的利益などを目的に踏むべき過程を飛ばしてしまったのが原因とも批判される。
さらには、生成AIが持つ「一見本物かわからないコンテンツを簡単に作り出せる」「大量生産が可能」という特性自体が、情報空間の健全化と著しく相性が悪いのではないとの意見もある。
【6. ハルシネーション(幻覚)問題】
生成AIにおける大きな問題として「ハルシネーション(hallucination、幻覚)」がある。一般的にハルシネーションとは、「生成AIが自信たっぷりな文面で間違った情報を回答してしまうこと」を指す。
ハルシネーションは、テキストの分類、情報抽出、そして特にテキストの生成で利用されるAI技術「言語モデル、Language Model・LM)」において問題となっている。
なお、この言語モデルのデータ量、計算量、パラメータ量を大幅に強化することで、より高度な言語理解を可能としたAIモデルを「大規模言語モデル(Large Language Model・LLM)」と呼ぶ。LLMが世界的に注目され活用が進んでいることから、本項目ではLLMの話をメインとする。現在注目されているLLMとしてOpenAIのChatGPTやxAIのGrokなどが挙げられる。
なお、この言語モデルのデータ量、計算量、パラメータ量を大幅に強化することで、より高度な言語理解を可能としたAIモデルを「大規模言語モデル(Large Language Model・LLM)」と呼ぶ。LLMが世界的に注目され活用が進んでいることから、本項目ではLLMの話をメインとする。現在注目されているLLMとしてOpenAIのChatGPTやxAIのGrokなどが挙げられる。
6-1. ハルシネーションによって引き起こされる主な問題
大規模言語モデル(LLM)のハルシネーションによって引き起こされる主な問題点は以下。
- ①.間違いや事実誤認が致命的となる場面において、生成AIが出力する情報を過度に信頼してしまうか鵜呑みにした結果、重大な問題を引き起こしてしまう。
- ②.生成AIが生成した間違いを含む情報が、生成AIに対して過度な信頼を有する人々によってSNS上などで拡散され、事実のように扱われてしまう。
- ③.AI生成されたハルシネーションを含む不正確な情報がインターネット上に大量投稿され続けた結果、情報を得る場としてのインターネットが破壊される可能性。
特に①の生成AIがハルシネーションを起こすという事実を知らないまま、もしくは生成AIに過度な信頼を抱いた上で利用・運用し、重大な結果を招いたケースについてはその事例がすでに存在している。
以下にその一例を挙げる。
以下にその一例を挙げる。
- 2022年11月~:航空会社エア・カナダが利用客向けにチャットボットを導入したが、忌引き割引について誤った情報を生成し、その内容を信じた利用客がチケットを予約したものの割引申請を拒否されたケース。エア・カナダ側は利用客から訴訟を起こされ、最終的に敗訴した。(*63)
- 2023年5月:アメリカの弁護士が裁判において、ChatGPTが誤って生成した実在しない判例を裁判資料として持ち込んでいたケース。弁護士は最終的に制裁金5000ドルを支払う事となった。(*64)
- 2023年10月:大阪市がLINEを通じた高齢者向けの支援事業として「大ちゃん」というチャットボットを導入するも、大阪万博について「中止になったみたいやで」と回答するなど事実とは異なる回答を連発したケース。(*65)(*66)
- 2024年11月:福岡県の魅力や特産品などを紹介するサイト「福岡つながり応援」に書かれていた情報が、存在しない祭りや他県の施設を紹介するなどAI製の不正確な情報が多いとネット上で指摘されたケース。同サイトは2024年11月1日にサービスを開始したものの、1か月後に閉鎖された。(*67)(*68)
6-2. ハルシネーションの原因
そもそもなぜハルシネーションが起こるのか?これは大規模言語モデル(LLM)の仕組みに起因している。
LLMの基本的な仕組みはこうである。
言語モデルは、人間が話したり書いたりする「言葉」や「文章」をもとに、単語の出現確率をモデル化する技術です。具体的には、大量のテキストデータから学習し、ある単語の後に続く単語が、どのくらいの確率で出現するのかを予測します。たとえば、「私の職業は」という文章の後に続く単語として、「医者です」「SEです」「保育士です」は確率として高いと判断し、「黄色」「海」などは低いと判断していき、言語をモデル化していきます。こうして言語モデルは、単語の出現確率を統計的に分析することで、人間の言語を理解し、予測することができるようになります。
引用元:LLM(大規模言語モデル)とは?生成AIとの違いや仕組みを解説(2024年2月29日:NECソリューションイノベータ)
つまりLLMは「ある単語の次に来る確率の高い単語を予測する技術」である。悪い言い方をしてしまうと、それっぽく言葉を継ぎ合わせているに過ぎず、単語の意味を理解した上で文章を構築しているわけではないため、「文章としては一見狂いがなくまともに読めても、書かれている情報が正しくなかったり、斜め上の回答をしてしまう」という事態が起きる。さらには、品質の悪い学習データを利用した場合についても、ハルシネーションが発生しやすくなるとされる。
そのため、「正しい情報」を求める時にLLMを利用し質問をするのは、技術の特性上あまり向いていないとも言える。LLMを使うにしても出力される情報の信頼性について別の記事・資料などを見てフェイクでないか検証したり、LLMではなく通常のネット検索や書籍などを利用するのもひとつの手だろう。
【ハルシネーションに関する記事・資料】
- ハルシネーション(野村総合研究所)
- 解説:生成AIのハルシネーションはなぜ起きるのか(2024年6月24日:MIT Technology Review)
【7. クリエイティブ関係における生成AIの問題点】
クリエイティブ関係において生成AIが引き起こしている・将来引き起こし得る分野を問わない共通の問題点についてまとめている。
7-1. クリエイティブと生成AIに関する問題の概要
この項目では、クリエイティブ・創作・エンターテインメントの業界・界隈において、現状の生成AIが現在どのような影響を与えているか、また将来与え得るかついて、その大まかな概要を記述する。
最初の項目でも述べたように生成AIは開発の際、大量のデータを収集(複製)する必要があり、そのデータは主にインターネットから集められている。この項目で言う「データ」とは基本的に「各クリエイターが制作した、もしくは企業などが権利を持つ作品」の事を指す。
生成AIの種類は、テキスト生成、画像生成、音楽生成、動画生成、音声生成など様々なものがあり、開発される生成AIの種類に応じてテキスト(文学作品、報道機関の記事、ウェブサイトの情報等)、画像(アート・イラスト、写真等)、音楽、映像(実写作品、アニメ作品等)、音声など多種多様なデータが収集されている。この収集段階を経て、生成AIが開発・リリースされ、AIサービスの利用者がAIコンテンツを作成・公開するという流れになっている。
生成AIの種類は、テキスト生成、画像生成、音楽生成、動画生成、音声生成など様々なものがあり、開発される生成AIの種類に応じてテキスト(文学作品、報道機関の記事、ウェブサイトの情報等)、画像(アート・イラスト、写真等)、音楽、映像(実写作品、アニメ作品等)、音声など多種多様なデータが収集されている。この収集段階を経て、生成AIが開発・リリースされ、AIサービスの利用者がAIコンテンツを作成・公開するという流れになっている。
これらによって(生成AIではない既存の手法で)作品を生み出すクリエイターや作品・コンテンツの権利を持つ企業といった権利者らにとってどんな問題が生じるのだろうか。
生成AIが持つ特性とそれによって生じる主な影響(問題点)について以下にまとめた。
- 【作品データの無許諾利用(開発・利用)】
特性:生成AIは開発時に大量の作品データを収集(複製)する必要がある。
影響①:生成AI開発で作品データが無断収集・利用され、生成AI利用の際自身と競合するAIコンテンツが生成・公開、これにより作品をAI開発に利用されたクリエイター・権利者が経済面などでダメージを受け、新規の作品制作などが困難となる。
影響②:作品が継続的に無許諾収集・利用されることによるAI企業からクリエイターへの搾取とも言える構造。
(※クリエイティブと生成AIの問題は「単に生成AI開発へ作品を無断利用されただけ」では基本発生せず、生成AIを用いてコンテンツを生成し公開する段階とセットになっている)
| + | もっと詳しく |
- 【海賊版の利用(開発)】
特性:生成AI企業は生成AI開発のためのデータ収集時、海賊版サイトを利用する事も少なくない。
影響:クリエイター、権利者が生成AI開発へ自身のコンテンツを利用されることについて何らかの形で拒否していたとしても、コンテンツが転載される事で、その意思表示が反映されにくくなる - 【大量生産(利用)】
特性:生成AIは、既存の手法と比較して極端な大量生産が可能。
影響:需要を大幅に上回る大量生産によって一つ一つの作品の価値が極端に低下する可能性
| + | もっと詳しく |
- 【クリエイター各個人の個性や特定のキャラクターの外見を高精度で再現可能なAIサービス・モデル(開発・利用)】
特性:各クリエイターが持ち、作品上に表出する個性(例えばイラストレーターの絵柄、作家の文体、声優の声質など)やある特定のキャラクターを高精度な再現を可能とするモデルが比較的簡単に作成可能である。またこれはネットを通して流通しており、誰でも使う事が出来る。
影響①:自身の個性を再現したAIコンテンツの大量流通によるごく短期間での表現の陳腐化
影響②:自身の個性を悪意を持つ者による嫌がらせに使われるリスク
影響③:クリエイター本人の名誉を傷つけるようなAIコンテンツの作成・流通
影響④:クリエイター本人が制作したと誤認されること、それによる悪影響
影響⑤:個性を再現したAIコンテンツとオリジナルのクリエイターとの半強制的な市場競合
| + | もっと詳しく |
- 【人間が作った作品とAIコンテンツの区別(利用)】
特性:生成AIは人間が制作した作品との見分けがつかないレベルで、見た目には高品質で高精度なAIコンテンツを作ることが出来る。
影響:人間とAIの見分けがつかない事による作品公開、販売、コンテスト、就職活動などにおける様々な混乱
もっと詳しく - 【著作権など知的財産権の形骸化(開発・利用)】
特性:多くの生成AI企業は著作権や肖像権などを有するコンテンツを生成AIの開発に利用しているとみられている。開発時に利用したデータの量や多種多様さに出力可能なコンテンツの種類や質も依存する生成AIの特性、生成AIサービスを用いてコンテンツを作成する事が簡単である事などから、権利侵害が疑われるコンテンツの作成も容易である。
影響:生成AIが持つ「取り扱いの簡単さ」「大量生産」によって、知的財産権の侵害が以前よりも頻繫に起こるようになり、権利者側の対処が追い付かなくなり、実質的に無法地帯と化す可能性。
| + | もっと詳しく |
- 【仕事への影響(利用)】
特性:生成AIは指示文の入力のみで容易に高品質なコンテンツを作成する事が可能であり、革命的・破壊的技術であると言える。これによってクリエイティブ関連の仕事に良くも悪くも大きな影響をもたらす事が予想できる。
影響①:クリエイターが失業する可能性。多くの生成AIはクリエイターらの作品を無断で利用した上で開発するため、「クリエイターからAIを通して価値を吸い取った上でその価値を作った本人は不要になる」という残酷な構図を作りだしてしまう。
影響②:AIの手軽さ、大量生産によって仕事の価値が著しく低下、クリエイターが経済的に立ち行かなくなる可能性。将来的に世代を超えて受け継がれてきたスキルや技術も途絶える可能性。
影響③:「AIが生み出したコンテンツの修正係」にクリエイターがなる事によって、あくまで「修正」である事を理由として、料金・賃金が減少してしまう可能性。
| + | もっと詳しく |
- 【海外AI企業による日本のコンテンツの無断利用(開発・利用)】
特性:米国や中国など海外のAI企業が日本のマンガやアニメ、ゲームといったコンテンツを無断利用した上で生成AIを開発、その生成AIから日本風味のキャラクターや表現手法が出力される。
影響:AIコンテンツは生成AI開発に無断で利用されたクリエイターや企業と市場競合する。そのため、海外AI企業が「日本製IP」「日本風の表現」を客寄せに利用してユーザーを集め利益を得、日本のクリエイターや企業が本来得られたであろう収益が失われる可能性。
生成AIの問題をクリエイター視点から見てみるとこうなる。
「作品を作って発表すれば即座に生成AI開発へ利用され、これは何らかの法規制でもない限り半永久的に続く。市場にはその生成AIから出力されたコンテンツが溢れ、それらと戦う必要がある。戦おうとして長い期間をかけ新しい表現を生み出しても作品データ収集・AI開発への利用、類似した表現を有するAIコンテンツの大量生産によって短期間で陳腐化する。個性を再現できる生成AIを利用した不適切な表現のAIコンテンツが公開される事や、AIを悪用した嫌がらせ行為などにも備えなければならない。これらの問題を防止する法規制などは道半ばであり、不十分であるなど八方塞がりの状態。」
「作品を作って発表すれば即座に生成AI開発へ利用され、これは何らかの法規制でもない限り半永久的に続く。市場にはその生成AIから出力されたコンテンツが溢れ、それらと戦う必要がある。戦おうとして長い期間をかけ新しい表現を生み出しても作品データ収集・AI開発への利用、類似した表現を有するAIコンテンツの大量生産によって短期間で陳腐化する。個性を再現できる生成AIを利用した不適切な表現のAIコンテンツが公開される事や、AIを悪用した嫌がらせ行為などにも備えなければならない。これらの問題を防止する法規制などは道半ばであり、不十分であるなど八方塞がりの状態。」
言ってみれば、「生成AIの発展」によって、(主に海外の)AI企業が(時には日本の代表的な作品にある優れた表現を利用して)利益を得たり、クライアントが現行の生成AIを活用して安く済ませたり、表現の受け手がAI作の面白い画像といったAIコンテンツを楽しんでいる裏には、自分の表現をフリー素材のごとくいいようにされ、本来得られるはずだった利益を奪われ、それを止められない環境の中で苦しんでいるクリエイターや権利者がいるのである。
この環境が続く事によって将来的にクリエイティブ業界を目指す若者は減り、世界や日本のクリエイティブが衰退するのではないかとする悲観論もある。しかしながら、必ずしも全てのクリエイターが生成AIの悪影響を受けるとは言えず、分野・職業などによっては活用している場合もあるため、一概には言えない部分も大きい。また、「生成AIの問題点」として挙げられているものの内、「以前にもあった(ので問題はない)」とする意見もあるが、一方生成AIの「今までとは異なる量の大量生産が可能」や「他人の表現を短期間かつ容易に再現できる」との特性によって、既にあった問題を比にならないレベルで深刻化させ、解決を困難にさせるとの指摘もあるため、これもまた一概には言えないであろう。
この項目では、生成AIが各クリエイティブの分野を越えてもたらす問題を解説した。各分野ごとの問題は以降の項目で詳細に解説する。
7-2. アート・イラストレーションに関する問題
⇒画像生成AIの問題点、特にイラストレーションなどに及ぼす影響についての詳細は当wikiの「画像生成AIは何が問題なのか?」をご覧ください。
2022年後半から本格的な画像生成AIがリリースされて以降、絵を描く人々に対し大きな悪影響を及ぼしている。絵描きと画像生成AIに関連した問題としてよく言われるのが「特定クリエイターの作風(絵柄)模倣問題」と「i2iなどを悪用した(いわゆる)トレパク問題」が挙げられる。
また、画像生成AIと絵描きに関してよくある勘違いとして「下手な絵は学習されない」というものがある。これは、画像生成AI開発企業・ユーザーによる作品の無断利用を警戒する絵描き達に対し、(特に技量的に未熟な人に向けて)嘲笑的・冷笑的なニュアンスで使用される事もある。
画像生成AIの学習(訓練、トレーニングとも称される)には主に2パターンあり、「基盤モデル構築時の学習」と「絵柄特化モデル(LoRAなど)作成時の学習」がある。LoRAは特定の要素を持つ生成物を出力するといった目的で、大量のデータで学習された基盤モデルを基に少量のデータを追加しAIモデルを調整するものである。
先述したように、基盤モデルの作成にはイラスト、写真など大量の画像データが必要となり、それらはインターネット上から集められるのが一般的だ。その大量のデータ内には技術的に未熟とされる絵も多く含まれているため、この点について「下手だから学習されない」は有り得ない。
画像生成AIとデータ収集に関して起きた出来事の一つとして、代表的な画像生成AI「Midjourney」の運営企業によって作成されたMidjourneyの学習に使用したアーティスト16000人のリストが流出したという事件がある。このリストにアンディ・ウォーホルや草間彌生など有名アーティストの名前が並ぶ中、募金活動の一環で絵を描いた6歳の男の子の名前が含まれていたことが話題となった。
⇒6歳児を含む1万6000人の作家リストが流出。AIの訓練に使用したとしてMidjourneyに非難が殺到(2024年1月5日:ARTnews Japan)
⇒6歳児を含む1万6000人の作家リストが流出。AIの訓練に使用したとしてMidjourneyに非難が殺到(2024年1月5日:ARTnews Japan)
また、AI画像を生成する際には指示文(プロンプト)を打ち込む必要があるが、逆に生成して欲しくない画像については「ネガティブプロンプト」を使い出力内容をコントロールする。代表的なネガティブプロンプトは「low quality(低クオリティ)」「bad anatomy(変な人体構造)」「low resolution/low res(低解像度)」などである。
⇒代表的な画像生成AI「Stable Diffusion」を開発した、英StabilityAI日本支社Xアカウントによるネガティブプロンプトの解説。
⇒代表的な画像生成AI「Stable Diffusion」を開発した、英StabilityAI日本支社Xアカウントによるネガティブプロンプトの解説。
では「絵柄特化モデル」はどうだろうか。civitaiなどといったAIモデル共有サイトでは有名イラストレーターなどを中心に、その作風(絵柄)などを真似た特化モデル(LoRA)などが画像生成AIユーザーによって作成され、共有されている。(ただ、基盤モデルと言われるものでも特定クリエイターの絵柄模倣が可能なものもある。)確かにわざわざ絵柄LoRAを作るのはその人の技術が優れていたり、魅力的な絵を描くからで、いわゆる「下手な絵」は一見学習されないように思える。とはいえ、数々の実績を持つプロ、ネット上に仕事半分趣味半分で投稿しているような素人・セミプロを問わず「少しでも魅力があると他者からみなされる絵を描くと絵柄LoRAモデルが作られてしまう」可能性は常にあるため、作品の実際のクオリティや作品への自己評価とは無関係にウォーターマークなどでの意思表示、GlazeなどといったAI利用阻害ツールなどを使うに越したことはないだろう。
⇒当Wiki「自作品を守るためにできること」も参照。
⇒当Wiki「自作品を守るためにできること」も参照。
7-3. 写真家・写真業界に関する問題
写真家からも生成AIに関する問題点が指摘されており、仕事への影響は当然のことながら人生をかけて作品を作っている写真家たちの作品が勝手にAI学習に用いられ、特定写真家の作風と似た生成物が出来てしまう事による心理的悪影響も指摘されている。さらに、ある写真素材の販売サイトに自らが撮った写真を提供している人からは、サイト側が撮影者側に明確な許諾なしに画像生成AIのAI学習に写真を使ったとして抗議しているケースもある。
一部の写真投稿・販売プラットフォームも生成AIの現状を問題視している。アメリカの大手写真素材販売企業Getty images(ゲッティ・イメージ)は、画像生成AIに自社が販売する画像データが無断で利用されることを問題視しており、画像生成AI開発企業Stability AIに対する訴訟やメディア・作家団体等と共に生成AIの濫用に対し規制を求める声明を発表する(ソース)など、動きを見せている。
⇒生成系AIに関連して発生した訴訟・法的対応の詳細は「生成系AIに関する訴訟・法的対応一覧」へ
7-4. 文芸に関する問題
テキストを生成するAIに対しては主に小説家と脚本家の人々から現状を問題視する声が上がっている。
特に海外においては盛んに抗議活動が行われている。全米脚本家協会(WGA)は2023年4月より映画制作会社等に対し環境改善を求めるストライキを行っており、その動機の一つとして「生成AI」の問題点を挙げている。同年7月にはアメリカの作家団体「全米作家協会」は生成AI企業に対し、「著作物のAI利用の際の許諾」「AIに利用された作家に対する公正な補償」「AIによる出力が合法か違法かに関わらず作家へ補償する事」書簡を発表した。なお、この書簡には8500名もの作家が署名している。
生成AIと文学界の葛藤は、デモや声明のみならず司法の場に持ち込まれている。2023年6月末にはアメリカ人作家2名がAI開発企業であるOpenAIに対し訴訟を提起した。同年7月初めにも有名コメディアンなども含まれるアメリカ人作家3名がOpenAIとFacebook等で知られる企業Metaに対し訴訟を起こしている。
⇒生成系AIに関連して発生した訴訟・法的対応の詳細は当wiki「生成系AIに関する訴訟・法的対応一覧」へ
生成AIは小説家や脚本家のみならず、ライター業の世界でも問題が発生している。あるフリーライターによると、「ChatGPTである程度文章を作れるようになったので1文字当たりの報酬を2円から1円に減らして欲しい」という要望がクライアントからあったという。
記事⇒「AI使うから報酬安く」フリーライターに突然の要求、違法の恐れも(2023年8月10日-朝日新聞)
記事⇒「AI使うから報酬安く」フリーライターに突然の要求、違法の恐れも(2023年8月10日-朝日新聞)
その他にもインターネットのショッピングサイトで生成AIによって作られた本を、特定作家の名前を勝手に使って販売するという事件も起きている。これに対し、作者はサイト側へ削除を要請したものの動きは鈍く、SNSで話題になってから初めて削除対応が行われたという。
記事⇒AIが書いた本が勝手に自分の名義で売られていたら…著者保護ルールが必要(2023年8月9日-GIZMODO)
記事⇒AIが書いた本が勝手に自分の名義で売られていたら…著者保護ルールが必要(2023年8月9日-GIZMODO)
7-5. 音楽に関する問題
音楽業界においても生成AIの問題点は大規模に指摘されている。
日本国内における音楽関連の権利団体として有名な日本音楽著作権協会(JASRAC)は、2023年7月に生成AIに対する考え方を発表している。その内容は、「人間の創造性を尊重すべきだ」「フリーライドを容認すべきではない」「国際的に協調すべきだ」「クリエイターの声を聞くべきだ」というものである。(ソース)
他にも、JASRACの理事を務める作曲家が文化庁の会議の席で現状の生成AIを問題視する発言を行っている。主に生成AIへ著作物を許可なしで利用してもいいとする根拠法とされる著作権法30条の4の問題点を指摘するものであり、「営利・商業目的であっても他者の著作物を無断利用できるのはおかしい」「許可を取って初めてAIに他者の制作した楽曲を利用できるようになるのが筋だ」「AI技術の進化によって他者の制作した音源から特定の楽器の音などを完璧に抜き出す事が出来るようになり、それに伴う著作隣接権の無視も横行」といった指摘を行っている。
1961年に13の音楽団体が結集して設立された団体、日本音楽作家団体協議会も2023年6月、現状を問題視する声明を発表した。この声明では「生成AI開発の過程における著作物の無断利用によって著作者が不利益を被る恐れ」「著作権法30条の4は生成AI技術が進化している現状に合っておらず、社会の状況に即した見直しが必要」「クリエイターを議論の場に参加させるべきだ」と述べられている。(ソース(PDF))
⇒生成AIに関してクリエイティブに関連する団体などが発した声明などは当wiki「生成系AIに対するクリエイティブ団体・企業の反応・対応」を参照。
7-6. 俳優・声優に関する問題
俳優・声優分野においても大きな問題が発生している。
アメリカのハリウッドにおいては、2023年7月より労働組合である「全米映画俳優連合(SAG-AFTRA)」主導で待遇の改善などを求めてストライキが行われているが、その理由の一つに生成AIが存在する。何が問題視されているのかというと「俳優の容姿や演技をスキャンし一日分だけのギャラを与え、そのスキャンされたデータの肖像権などは制作会社側が有し、生成AI技術によって無制限に利用する」という事態が起きようとしており、これがまかり通ってしまえば俳優側がキャリアを積むことも困難になる懸念があるためだ。
動きは日本国内でも存在する。1967年に設立され、理事長を俳優の西田敏行、副理事長を女優の水谷八重子と声優の野沢雅子が務める俳優団体「日本俳優連合」では2023年5月に外画・動画部会が主導となって「AI対策プロジェクト」を発足した。同年6月、同団体は生成AIについての声明を発表した。内容は「EUのAI法を参照したガイドラインの策定」「AI学習の素材は著作者が許可を与えた物のみとして著作権法30条の4の運用見直しを」「AI生成物である事の明示」「AIの表現分野への進出は一定のルールを設ける」「声の肖像権の確立」を求めるものである。(ソース)
声優に対しての被害も深刻だ。声優が自らの声を無断で抽出され、本人が思ってもいないような過激な事を言わされたり、ボイス生成AIを用いた声優への攻撃も行われている。
⇒生成AIに関してクリエイティブに関連する団体などが発した声明などは当wiki「生成系AIに対するクリエイティブ団体・企業の反応・対応」を参照。
7-7. プログラムに関する問題
プログラミングの世界でも騒動があり、アメリカで「Github Copilot」というコードの続きを生成するAIが開発されたが、これについて同国で訴訟が発生している。
⇒生成系AIに関連して発生した訴訟・法的対応の詳細は当wiki「生成系AIに関する訴訟・法的対応一覧」へ
7-8. 報道機関に関する問題
マスメディアなどの報道機関でも生成AIの問題は深刻なものとして受け止められている。
問題としては主に以下のような点が挙げられている。
- 生成AI開発企業がメディア側への許諾も対価もなく無断で記事を生成AIの開発に利用し、その記事を再構成したAI生成コンテンツがメディアの記事と市場競合する(メディアが公開した有料記事と文章や構成が似ている記事が生成AI検索エンジンによって生成されていたとのケースもある。(*69))
- AI生成されたフェイクニュースが溢れることによって言論空間が混乱する
- 質問や検索の内容に応じて回答となるテキストを生成し、その回答の参考にされた記事を出典表記している生成AIサービスにおいて、実際の記事内容とは異なる不正確な生成結果を出力(ハルシネーション)した状態で出典が表記された場合、メディア側に落ち度がないにも関わらず出典となったメディアの信頼性も疑われてしまう
ウェブ上の記事の要約を生成する機能を持つAI検索エンジンにおいては、要約を生成する際に報道機関などのサイトに書かれた情報を利用するものの、ユーザーがAI要約で満足し情報源のサイトへ行くことが無くなり、サイトへのクリックなどで得られたはずの収益が失われる可能性が指摘されている。実際に、AI企業とパブリッシャーのライセンス契約を仲介する企業TollBitが行った調査では、AI検索エンジンは従来の検索エンジンに比べ96%も減少させているとの結果が発表された。
また、生成AI開発においては、ウェブクローラーというボットを用いてインターネット上のデータをスクレイピングして集める(複製する)ことが主流となっているが、一方的なデータ収集を防ぐため、メディア側によるrobots.txtなどを用いたAI学習データ収集用クローラーのアクセス拒否の措置が進んでいる。ただし、クローラーに関してはAI企業が利用しているウェブクローラーを開示していない事や検索向けインデックスの作成と生成AI開発用クローラーが同じボットを利用しているケースも存在するなど、解決には程遠い。
さらには、クローラーがかなりの回数サイトへアクセスしてくるため、サイト側のサーバーコストを増加させるという問題も引き起している。(*70)
さらには、クローラーがかなりの回数サイトへアクセスしてくるため、サイト側のサーバーコストを増加させるという問題も引き起している。(*70)
AI企業は、メディア側がジャーナリズムのため行った多額の投資によって作られた記事などのコンテンツをインターネット越しに無断利用し、メディアの記事とは内容がやや異なるAI要約を生成するサービスを運営する。AI検索サービスはメディアと直接的に競合し、AI検索サービスの利用者数が増えれば増えるほどメディア側のアクセス数も減少し収益もそれに従って減る。おまけに過剰なアクセスによってメディア側のサーバーコストも増える。
この現状に対し、世界各国のメディアやその関連団体から様々な動きが出ている。
海外においては、世界100ヵ国で76の各国新聞協会などが加盟する団体である世界新聞協会(WAN-IFRA)は、2023年9月6日に日本や米国、ヨーロッパなど世界26か国のメディア団体と共に生成AIの開発・利用について知的財産の保護や透明性を求める内容の声明を発表した。
⇒世界AI原則(Global Principles on Artificial Intelligence・仮訳)(2023年9月6日:日本新聞協会)
⇒生成AI開発や著作権に「世界原則」…知的財産保護や透明性確保要求、日本新聞協会も賛同(2023年9月6日:読売新聞)
⇒世界AI原則(Global Principles on Artificial Intelligence・仮訳)(2023年9月6日:日本新聞協会)
⇒生成AI開発や著作権に「世界原則」…知的財産保護や透明性確保要求、日本新聞協会も賛同(2023年9月6日:読売新聞)
国内でも日本新聞協会が2023年5月に言論空間の混乱や個人情報、著作権上の問題を指摘する声明を発表するなど、生成AIの問題を解決するための動きを進めている。
⇒[PDF]生成AIによる報道コンテンツ利用をめぐる見解(2023年5月17日:日本新聞協会)
⇒[PDF]生成AIによる報道コンテンツ利用をめぐる見解(2023年5月17日:日本新聞協会)
また、いわゆる基盤モデルの構築時の記事無断利用のほかにも、RAG(検索拡張生成)における報道記事無断利用も問題視されている。
⇒生成AIにおける報道コンテンツの無断利用等に関する声明(2024年7月17日:日本新聞協会)
⇒生成AIにおける報道コンテンツの無断利用等に関する声明(2024年7月17日:日本新聞協会)
メディア側も声明を発表するのみならず、生成AI開発時における記事データの無断利用に関してAI企業を提訴している。
訴訟の一例として、ニューヨークタイムズが2023年12月末にChatGPTの開発などで知られるAI企業OpenAIとマイクロソフトを提訴したもの、米地方紙8社連合が2024年4月にOpenAI・マイクロソフトを提訴したもの、2024年11月にカナダメディア5社が合同でOpenAIを提訴したものなどが挙げられる。
⇒各訴訟についての詳細は当Wiki「生成AIに関する訴訟・法的対応一覧」へ。
訴訟の一例として、ニューヨークタイムズが2023年12月末にChatGPTの開発などで知られるAI企業OpenAIとマイクロソフトを提訴したもの、米地方紙8社連合が2024年4月にOpenAI・マイクロソフトを提訴したもの、2024年11月にカナダメディア5社が合同でOpenAIを提訴したものなどが挙げられる。
⇒各訴訟についての詳細は当Wiki「生成AIに関する訴訟・法的対応一覧」へ。
一方、AI企業がメディア各社に記事利用料を支払う取り組みも進んでいる。OpenAIはニューズ・コープやフィナンシャルタイムズといった欧米メディアと利用契約を結んだ他、FacebookやインスタグラムなどのSNS運営で知られるMetaもロイターと提携を行った。生成AIを利用した検索システム事業を展開する企業perplexityも、対価還元プログラムを実施している。
7-9 AI生成コンテンツの著作権問題
生成AI問題の一つの争点として、AI生成コンテンツに著作権が認められるかどうかというものがある。これを巡る関連機関の判断がすでにいくつかの国で出ているが、それぞれの国の法律やAI生成コンテンツの形態により対応が分かれている。
また、著作権と言う難しい話を扱うのでここに記載されたもの以外にも脚注に添付した記事や資料を読んだり、それぞれ個人で調べることを強く推奨する。
また、著作権と言う難しい話を扱うのでここに記載されたもの以外にも脚注に添付した記事や資料を読んだり、それぞれ個人で調べることを強く推奨する。
以下で各国における動きを記載する。
1.アメリカでの動き
アメリカでは、AI生成コンテンツに対し著作権局(U.S. Copyright Office,USCO)へ著作権登録を求める動きがいくつかあったが、却下されたり一部だけが認められる形になるなど、対応が分かれている。
なお著作権局は、2023年3月にAI生成コンテンツと著作権に関するガイダンス(Copyright Registration Guidance: Works Containing Material Generated by Artificial Intelligence)を発表した。
- 「A Recent Entrance To Paradise」
「Creativity Machine(DABUS)」というアルゴリズムによって作成されたAI画像作品で、AI研究者であるスティーブン・セイラー氏が著作権局へ著作権登録を申請したが、2022年2月に申請が拒否された。(*71)
その後セイラー氏は著作権局へ訴訟(Thaler v. Perlmutter)を起こすも2023年8月に同氏の主張を否定する判決が下された。(*72)また、控訴審においても「著作権で保護されるのに必要な人間の著作権の要素が含まれていない」として裁判所は1審の判決を支持し、著作権を認めない決定を2025年3月に下した。セイラー氏は判決に不満を持っており上告する予定である。(*73)(*74)
- 「Theatre D'opera Spatial」
画像生成AI「Midjourney」などを利用し制作されたデジタル絵画で、ジェイソン・アレン(Jason M. Allen)氏によって制作された。2022年8月に米コロラド州の美術品評会で1位を獲得、このことは画像生成AIが本格的に話題になり始めていた時期であったためAIと創作について当時大きな議論を呼んだ。
アレン氏は著作権局へ同作品の著作権登録を求めたが、2023年9月に「AI生成された素材を含む作品を著作権登録するには、著作権登録申請の対象からその素材を除外する旨を明示する必要があるが、同作品の作者はしなかった」などとして著作権局側は登録を拒否した。同氏は「テキストプロンプトを少なくとも624回入力し、同時にAdobe Photoshopなどを利用し多数の修正も行った」と主張したものの、著作権局は登録拒否の理由として、「Midjourneyは人間の様に文法や文章構造、単語を理解している訳ではないので、Midjourneyはプロンプトを特定の表現を作成するための具体的な指示として解釈していない」などを挙げた。(*75)(*76)
アレン氏は2024年10月に著作権局に対し法的措置を取ると発表した。(*77)
- 「Zarya of the Dawn」
クリス・カシュタノバ(Kris Kashtanova)氏が画像生成AI「Midjourney」などを利用して制作したグラフィックノベル(漫画の一種)。カシュタノバ氏は、2022年9月に一度著作権局より著作権登録を認められたと発表した(*78)が、2023年2月にグラフィックノベル内の画像については「作者は各画像の構成や内容の『指導』をしたと主張したが、説明された制作プロセスを踏まえれば『画像の伝統的著作者の要素』を創作したのはMidjourneyである」などとして著作権登録を受けず、テキストと記述、視覚的要素の選択、調整、配置などは著作権を認められた。(*79)
2.中国での動き
中国では、インターネット上において無断で転載されたAI画像に対し画像作成者が起こした訴訟で、裁判所側が画像の著作物性と著作権侵害を認め作成者側が勝訴した。
- 「春风送来了温柔(春風が優しさを運んでくる)」
画像生成AI「Stable Diffusion」で作成されたAI画像で、作成者である原告はその画像を中国のSNS「小紅書(RED BOOK)」にアップロードした。その後、バイドゥ(百度)が運営する創作プラットフォーム「百家号」で、被告側が発表した文章「桃の花の中の三月の愛情」内に原告が画像に付した署名が取り除かれる形で利用されているのを発見し、北京の裁判所に損害賠償を求める訴訟を提起した。2023年11月、裁判所は画像の著作物性と著作権侵害を認める判決を下した。(*80)
3.日本での動き
日本国内においては、アメリカや中国のようにAI生成コンテンツと著作権をめぐる裁判などは(当Wiki編集者が確認する限り)起こっていないが、2024年3月に文化庁が発表した資料「AIと著作権について(PDF)」の中でAI生成コンテンツの著作物性の判断基準として以下のような条件を挙げている。(AI生成コンテンツの著作物性については資料39~40ページにある。)
| + | 長いので折りたたみ |
7-10 既存のコンテンツとAI生成コンテンツの見分けが難しい事に関する問題
生成AIコンテンツは、人間が既存の手法を用いて作成した作品と見分けがつかないレベルにまで進化している。これによる社会的混乱がすでに散見されている。また、AI生成物と実在する物の見分けが付きにくい事に関しては、ディープフェイクによる社会の混乱など多様な問題をもたらすが、本項目においてはクリエイティブと生成AIに纏わる問題のみを取り上げる。
1.実際に起きている問題、今後懸念される問題
以下がクリエイティブと生成AIに関して起きているもしくは将来起こりうる問題の一覧。
- 既存のクリエイターへのなりすまし行為。
- 人間の作品とAI生成作品の識別において、確実に見分けられる手段が存在しないこと。人間の目や耳、AI生成物検知ツールなどを使って区別しようにも、AI生成物のクオリティ向上や検知ツールを回避する技術の進歩などによって結局はいたちごっこになる。
- 生成AIを利用せず作品制作を行っているにも関わらず、AI生成物のクオリティ向上に伴う判別の難易度向上、または悪意や根拠薄弱な断定に基づいて生成AIを利用していると不当に疑われてしまうこと。
- 既存の手法で作成された作品を購入したはずがAI製だったケース。
- 生成AI製作品の参加を禁ずるアートコンテストなどにおいて、AI生成コンテンツであることを隠して応募されていた場合の混乱。
- 特にクリエイティブ系企業の社員採用(就職活動)において、応募者側がポートフォリオなどにAI生成作品である旨を表記しない状態で掲載、実績が誤認された結果、企業側が求めるスキルとは異なるスキルを持った応募者を誤って採用、その採用後に起こる混乱。(実技試験の導入などによってこのトラブルは回避可能とされる)
- 一般的にAI生成コンテンツは著作権が認められにくいとされるが、それによって生じる作品の発注、制作、発表、利用時における権利関係の混乱。作品の作成者が意図的かどうかを問わずAI生成かを隠蔽していた場合や、作品の発注・利用者がAI製であることを知らなかった場合はなおさら深刻に。
- AI生成作品の著作権登録を試みようとする行為。主な問題は以下の二つに分けられる。
①制作者がAI生成作品であることを公表せず登録を試みる可能性
②AI生成作品に著作権が付与される条件が不確実であること
2.著作権法上の課題
AI生成コンテンツと既存の手法で作成された著作物との見分けが難しいことに関する、著作権法上の課題として以下のような問題が指摘されている。
以下は、文化庁が2024年1月に発表した文書「AIと著作権に関する考え方について(素案)」へ募集したパブリックコメントに対し、日本弁護士連合会が同年2月に提出した意見書。うち、「僭称 著作物問題」について記載された箇所を抜粋する。
3 いわゆる「僭称著作物問題」について
人間による指示に何ら創作意図や創作的寄与がなく、AIが自律的に生成した単純なAI生成物は、機械的作業の結果に過ぎないため、基本的には著作物性が認められないとされている。ところが、生成AIでは、人間の創作物と見分けのつかない情報が生成可能となっており、そのため、AIが生成したものであるため著作物と認められないコンテンツについて、人間が創作したものであると明示又は黙示に僭称されるという問題が生じ得る(いわゆる「僭称著作物問題」)。
このような行為が許され僭称が発覚しないままとなれば、著作権で保護されないものが保護され、実在しない著作者又は著作者でない者に著作者人格権が与えられるという形となってしまい、しかも著作者が実在しない場合には、権利の存続期間もさらなる虚構を重ねることとなってしまう。また、生成AIでは人間より遥かに高い生産性で創作物が生成可能となっており、AI利用者による情報独占も懸念される。さらに、僭称が発覚した場合には、僭称されたコンテンツのライセンス契約やビジネススキームが崩壊する恐れも生じる。以上からすると、僭称著作物問題については、本素案においても債務不履行責任や不法行為責任等の民法上の責任及び詐欺罪の成立可能性について言及されているところではあるが(本素案35頁~36頁)、著作権制度の根幹に関わり、かつ、著作権関連ビジネスにも重大な影響を与え得るものであると考えられるため、今後、重要問題として位置付けた上で議論を継続することが意識されるべきである。
なお、著作権法第121条は、著作者でない者の名を著作者と僭称して複製物を頒布することを罰しているが、著作物でないAI生成物に同条が適用されるかは解釈若しくは法改正に委ねられるところ、僭称著作物問題の検討にあたっては、この著作権法第121条についても議論の対象となると考えられる。
- 「AIと著作権に関する考え方について(素案)」に対する意見書(2024年2月16日-日本弁護士連合会)
3.ネット上におけるAI利用指摘問題(いわゆる魔女狩り問題)(編集中)
編集中
7-11 クリエイター関連で提唱されている生成AI規制案
【8. 学術・研究に関する問題】
生成AIは容易に偽情報を作ることが出来るが、この問題は学術・研究の分野でも悪影響を及ぼしている。
8-1. AI生成された偽の研究結果
実験結果の画像などを生成AIで作った論文が増えることで科学への信頼が揺らぐ可能性が指摘されており、また見抜こうにも難しいため対応に苦慮している。
論文の執筆において、多くの学術誌はテキスト部分について特定の状況下のみで生成AIの利用を認めているものの、実験データや画像をAI生成する事は信頼性を根本から壊すため認められる可能性は低いとされる。すでに偽論文を量産し販売するペーパーミル(論文工場)が生成AIを用い論文を大量作成しているとの疑いもある。(*81)(*82)
具体的な事例としては、中国の研究チームが2024年2月に発表した論文の中に画像生成AI「Midjourney」で作られた破綻していたり意味不明な描写を含む画像3枚が添付されていたというものがある。この事件ではAI生成されたネズミの性器が巨大であることが注目されたが、より精巧な画像が根幹の部分で使われる可能性も考慮すべきだろう。(*83)(*84)
8-2. ハゲタカジャーナル問題の深刻化
編集中
【9. 教育に関する問題】
編集中
【10. 失業・働き方に関する問題】
編集中
【11. 電力・環境に関する問題】
編集中
【12. 脱獄・犯罪利用】
編集中
【13. その他の問題点】
機械学習への悪影響
編集中
